Intrinsic Evaluation of Summarization Datasets
Rishi Bommasani, Claire Cardie
Summarization Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
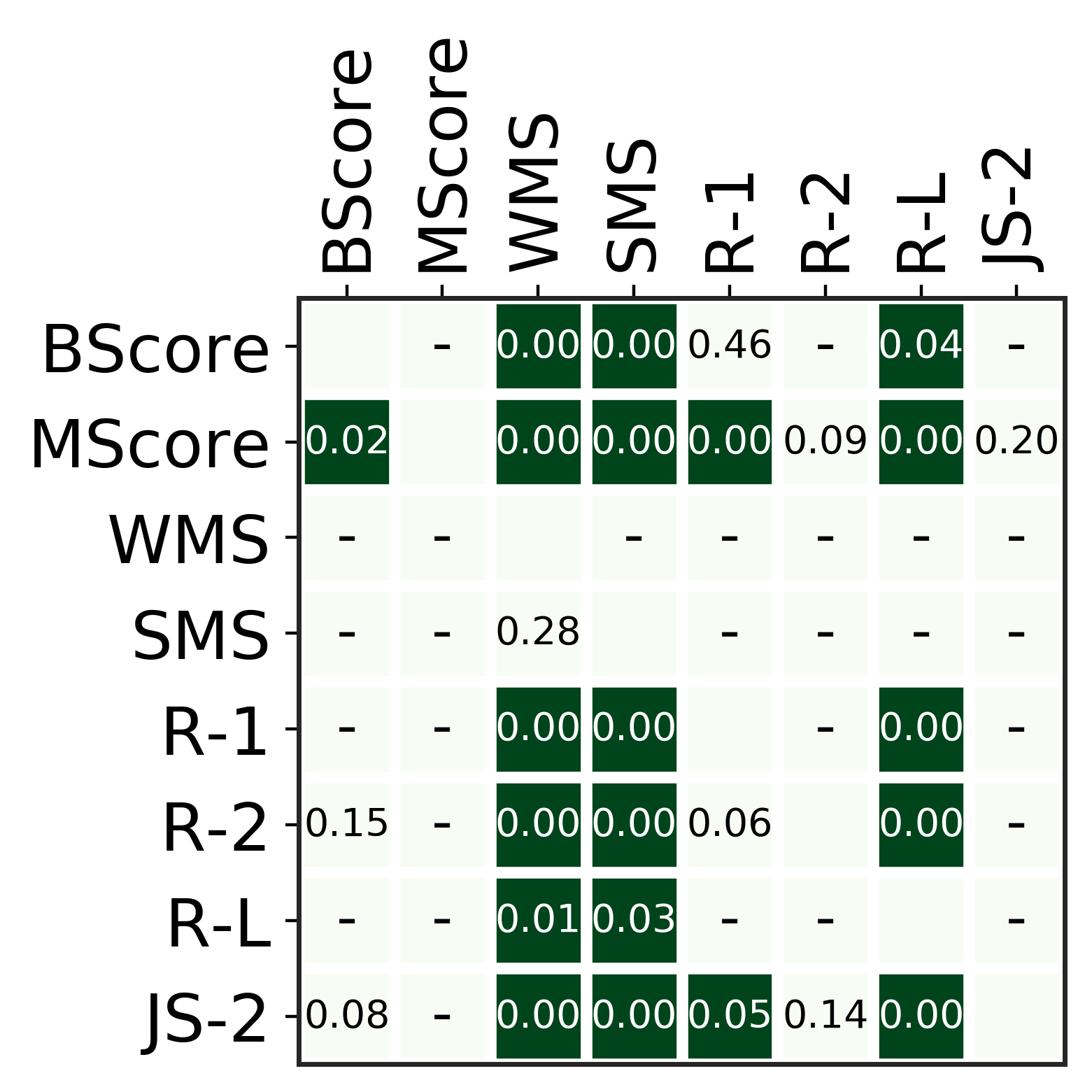
High quality data forms the bedrock for building meaningful statistical models in NLP. Consequently, data quality must be evaluated either during dataset construction or *post hoc*. Almost all popular summarization datasets are drawn from natural sources and do not come with inherent quality assurance guarantees. In spite of this, data quality has gone largely unquestioned for many of these recent datasets. We perform the first large-scale evaluation of summarization datasets by introducing 5 intrinsic metrics and applying them to 10 popular datasets. We find that data usage in recent summarization research is sometimes inconsistent with the underlying properties of the data. Further, we discover that our metrics can serve the additional purpose of being inexpensive heuristics for detecting generically low quality examples.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Interpretable Multi-dataset Evaluation for Named Entity Recognition
Jinlan Fu, Pengfei Liu, Graham Neubig,
Iterative Feature Mining for Constraint-Based Data Collection to Increase Data Diversity and Model Robustness
Stefan Larson, Anthony Zheng, Anish Mahendran, Rishi Tekriwal, Adrian Cheung, Eric Guldan, Kevin Leach, Jonathan K. Kummerfeld,

Easy, Reproducible and Quality-Controlled Data Collection with CROWDAQ
Qiang Ning, Hao Wu, Pradeep Dasigi, Dheeru Dua, Matt Gardner, Robert L Logan IV, Ana Marasović, Zhen Nie,

Re-evaluating Evaluation in Text Summarization
Manik Bhandari, Pranav Narayan Gour, Atabak Ashfaq, Pengfei Liu, Graham Neubig,