A Visually-grounded First-person Dialogue Dataset with Verbal and Non-verbal Responses
Hisashi Kamezawa, Noriki Nishida, Nobuyuki Shimizu, Takashi Miyazaki, Hideki Nakayama
Dialog and Interactive Systems Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
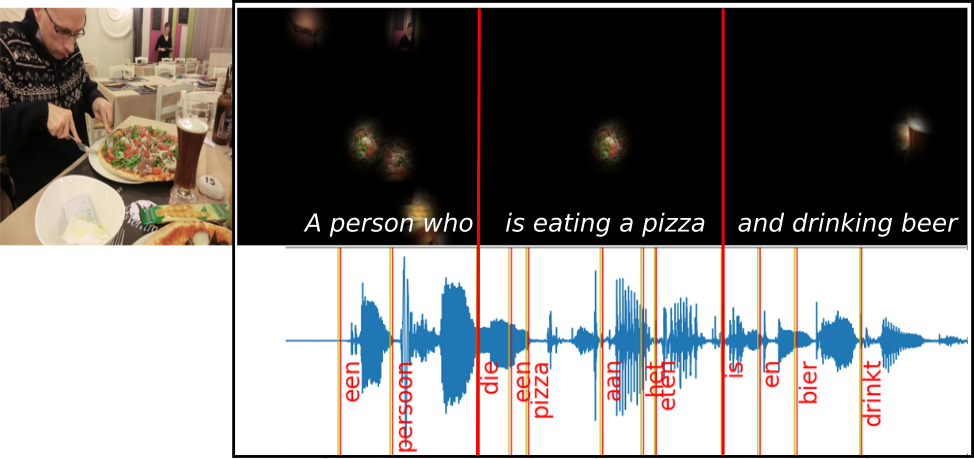
In real-world dialogue, first-person visual information about where the other speakers are and what they are paying attention to is crucial to understand their intentions. Non-verbal responses also play an important role in social interactions. In this paper, we propose a visually-grounded first-person dialogue (VFD) dataset with verbal and non-verbal responses. The VFD dataset provides manually annotated (1) first-person images of agents, (2) utterances of human speakers, (3) eye-gaze locations of the speakers, and (4) the agents' verbal and non-verbal responses. We present experimental results obtained using the proposed VFD dataset and recent neural network models (e.g., BERT, ResNet). The results demonstrate that first-person vision helps neural network models correctly understand human intentions, and the production of non-verbal responses is a challenging task like that of verbal responses. Our dataset is publicly available.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Generating Image Descriptions via Sequential Cross-Modal Alignment Guided by Human Gaze
Ece Takmaz, Sandro Pezzelle, Lisa Beinborn, Raquel Fernández,
TOD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogue
Chien-Sheng Wu, Steven C.H. Hoi, Richard Socher, Caiming Xiong,
Where Are You? Localization from Embodied Dialog
Meera Hahn, Jacob Krantz, Dhruv Batra, Devi Parikh, James Rehg, Stefan Lee, Peter Anderson,

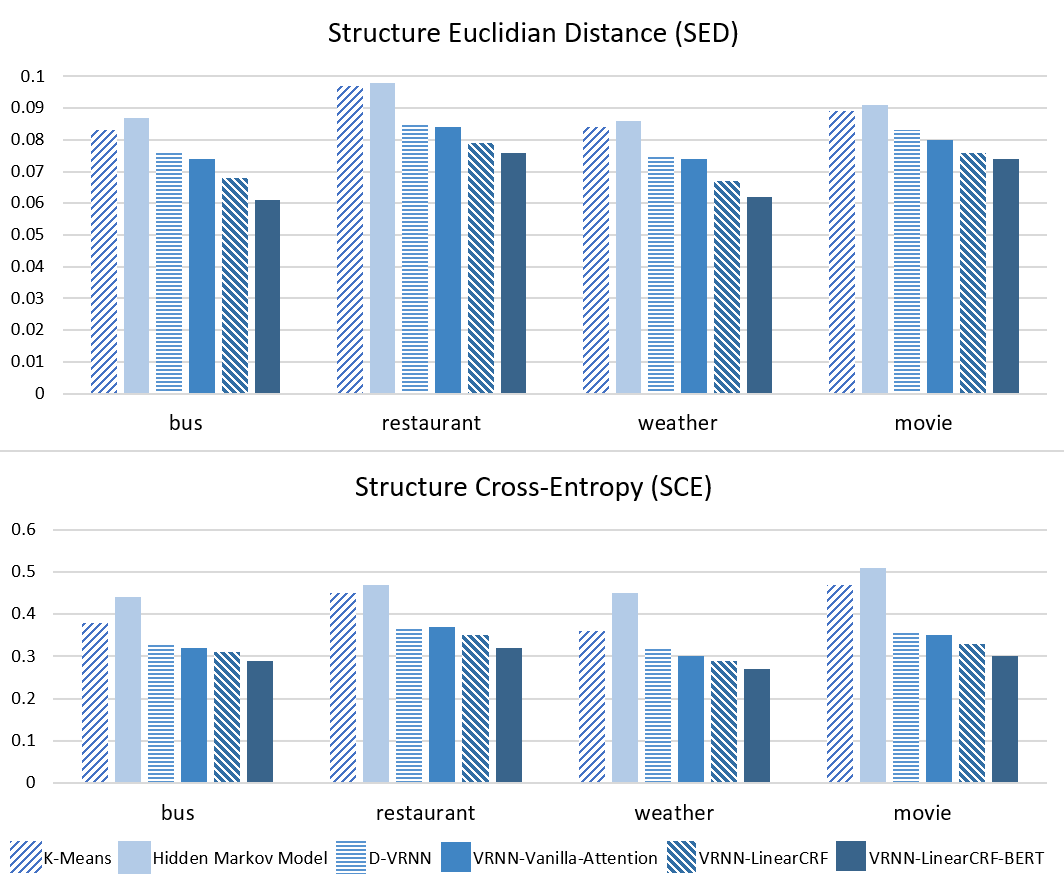
Structured Attention for Unsupervised Dialogue Structure Induction
Liang Qiu, Yizhou Zhao, Weiyan Shi, Yuan Liang, Feng Shi, Tao Yuan, Zhou Yu, Song-Chun Zhu,