On Extractive and Abstractive Neural Document Summarization with Transformer Language Models
Jonathan Pilault, Raymond Li, Sandeep Subramanian, Chris Pal
Summarization Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
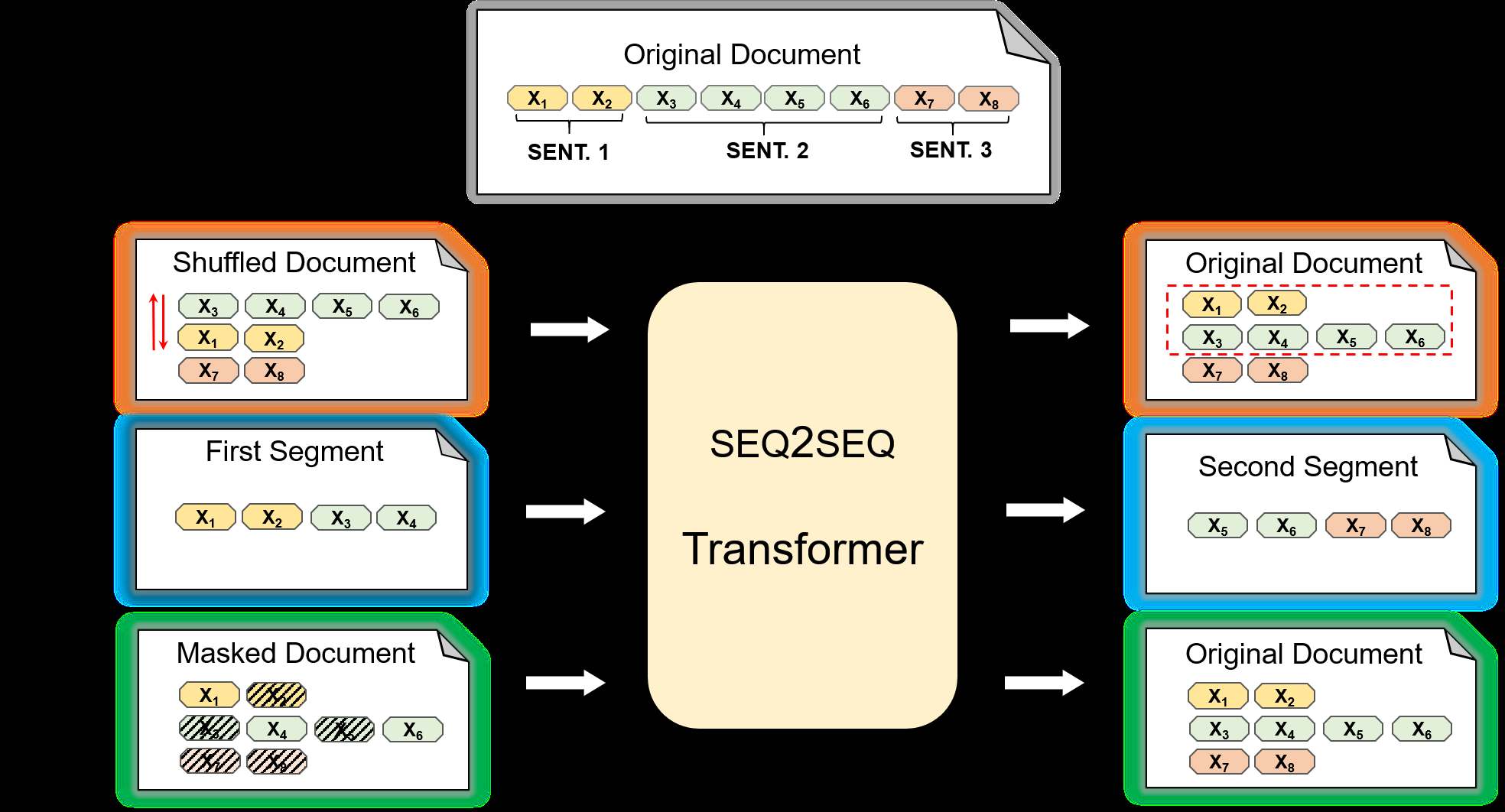
We present a method to produce abstractive summaries of long documents that exceed several thousand words via neural abstractive summarization. We perform a simple extractive step before generating a summary, which is then used to condition the transformer language model on relevant information before being tasked with generating a summary. We also show that this approach produces more abstractive summaries compared to prior work that employs a copy mechanism while still achieving higher ROUGE scores. We provide extensive comparisons with strong baseline methods, prior state of the art work as well as multiple variants of our approach including those using only transformers, only extractive techniques and combinations of the two. We examine these models using four different summarization tasks and datasets: arXiv papers, PubMed papers, the Newsroom and BigPatent datasets. We find that transformer based methods produce summaries with fewer n-gram copies, leading to n-gram copying statistics that are more similar to human generated abstracts. We include a human evaluation, finding that transformers are ranked highly for coherence and fluency, but purely extractive methods score higher for informativeness and relevance. We hope that these architectures and experiments may serve as strong points of comparison for future work. Note: The abstract above was collaboratively written by the authors and one of the models presented in this paper based on an earlier draft of this paper.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Multi-Fact Correction in Abstractive Text Summarization
Yue Dong, Shuohang Wang, Zhe Gan, Yu Cheng, Jackie Chi Kit Cheung, Jingjing Liu,
Evaluating the Factual Consistency of Abstractive Text Summarization
Wojciech Kryscinski, Bryan McCann, Caiming Xiong, Richard Socher,

Q-learning with Language Model for Edit-based Unsupervised Summarization
Ryosuke Kohita, Akifumi Wachi, Yang Zhao, Ryuki Tachibana,

Pre-training for Abstractive Document Summarization by Reinstating Source Text
Yanyan Zou, Xingxing Zhang, Wei Lu, Furu Wei, Ming Zhou,