Evaluating the Factual Consistency of Abstractive Text Summarization
Wojciech Kryscinski, Bryan McCann, Caiming Xiong, Richard Socher
Summarization Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
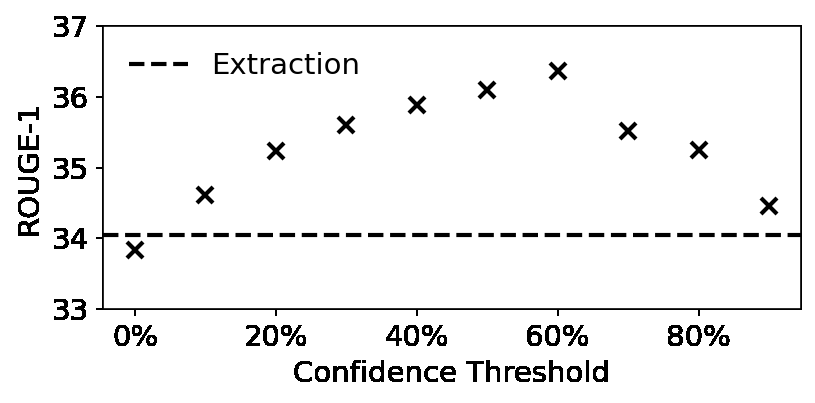
The most common metrics for assessing summarization algorithms do not account for whether summaries are factually consistent with source documents. We propose a weakly-supervised, model-based approach for verifying factual consistency and identifying conflicts between source documents and generated summaries. Training data is generated by applying a series of rule-based transformations to the sentences of source documents.The factual consistency model is then trained jointly for three tasks: 1) predict whether each summary sentence is factually consistent or not, 2) in either case, extract a span in the source document to support this consistency prediction, 3) for each summary sentence that is deemed inconsistent, extract the inconsistent span from it. Transferring this model to summaries generated by several neural models reveals that this highly scalable approach outperforms previous models, including those trained with strong supervision using datasets from related domains, such as natural language inference and fact checking. Additionally, human evaluation shows that the auxiliary span extraction tasks provide useful assistance in the process of verifying factual consistency. We also release a manually annotated dataset for factual consistency verification, code for training data generation, and trained model weights at https://github.com/salesforce/factCC.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
On Extractive and Abstractive Neural Document Summarization with Transformer Language Models
Jonathan Pilault, Raymond Li, Sandeep Subramanian, Chris Pal,

Factual Error Correction for Abstractive Summarization Models
Meng Cao, Yue Dong, Jiapeng Wu, Jackie Chi Kit Cheung,

Compressive Summarization with Plausibility and Salience Modeling
Shrey Desai, Jiacheng Xu, Greg Durrett,