MUTANT: A Training Paradigm for Out-of-Distribution Generalization in Visual Question Answering
Tejas Gokhale, Pratyay Banerjee, Chitta Baral, Yezhou Yang
Language Grounding to Vision, Robotics and Beyond Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
While progress has been made on the visual question answering leaderboards, models often utilize spurious correlations and priors in datasets under the i.i.d. setting. As such, evaluation on out-of-distribution (OOD) test samples has emerged as a proxy for generalization. In this paper, we present \textit{MUTANT}, a training paradigm that exposes the model to perceptually similar, yet semantically distinct \textit{mutations} of the input, to improve OOD generalization, such as the VQA-CP challenge. Under this paradigm, models utilize a consistency-constrained training objective to understand the effect of semantic changes in input (question-image pair) on the output (answer). Unlike existing methods on VQA-CP, \textit{MUTANT} does not rely on the knowledge about the nature of train and test answer distributions. \textit{MUTANT} establishes a new state-of-the-art accuracy on VQA-CP with a $10.57\%$ improvement. Our work opens up avenues for the use of semantic input mutations for OOD generalization in question answering.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Don't Read Too Much Into It: Adaptive Computation for Open-Domain Question Answering
Yuxiang Wu, Sebastian Riedel, Pasquale Minervini, Pontus Stenetorp,

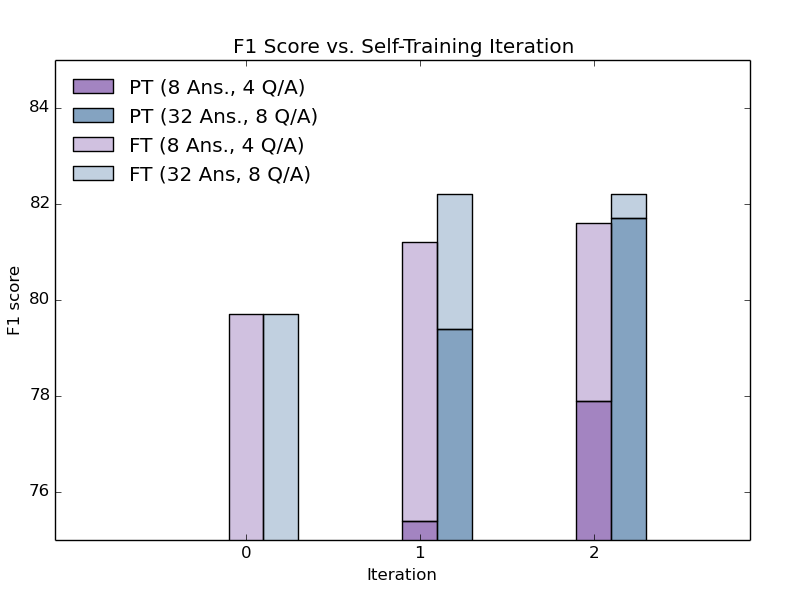
Unsupervised Adaptation of Question Answering Systems via Generative Self-training
Steven Rennie, Etienne Marcheret, Neil Mallinar, David Nahamoo, Vaibhava Goel,
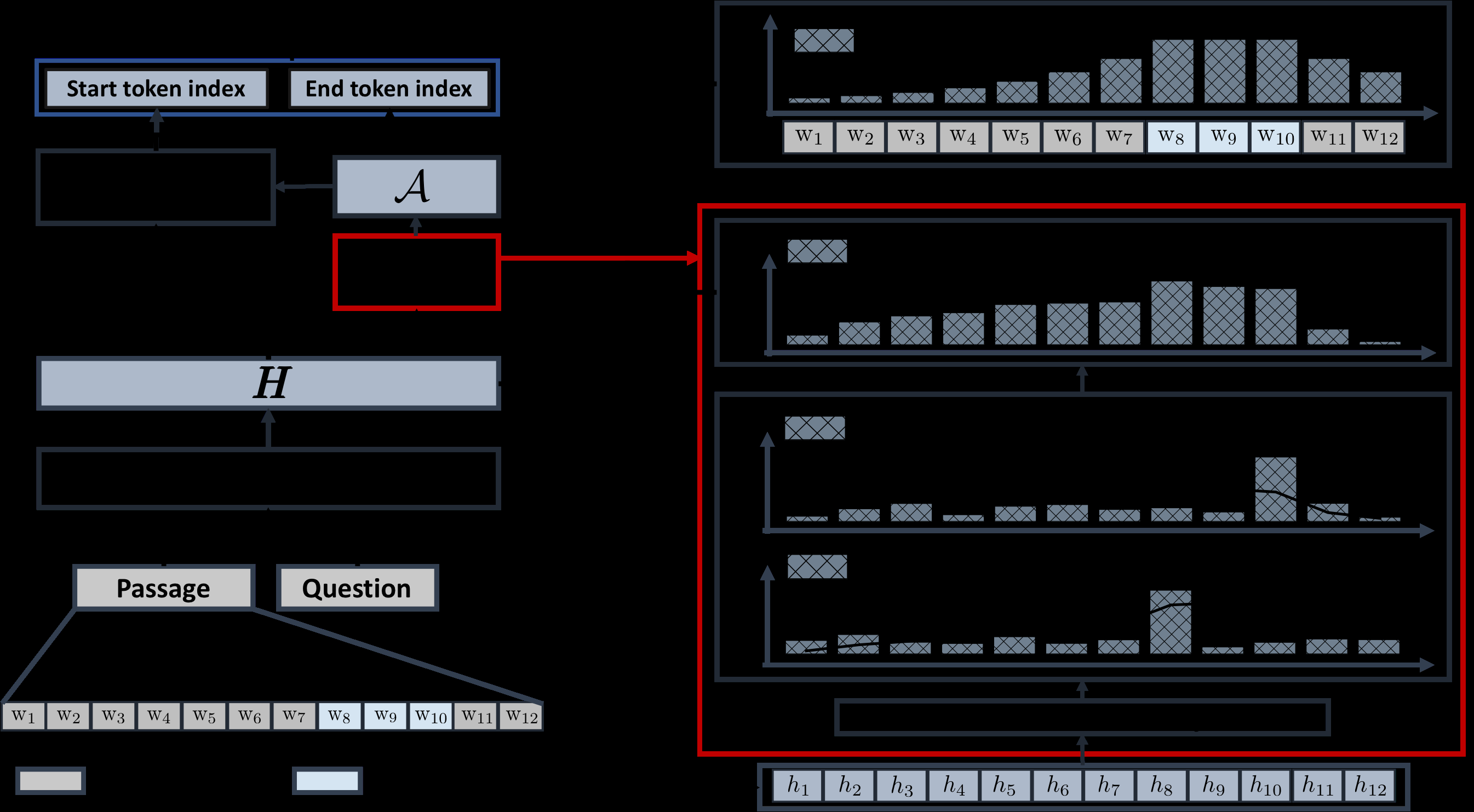
Context-Aware Answer Extraction in Question Answering
Yeon Seonwoo, Ji-Hoon Kim, Jung-Woo Ha, Alice Oh,
oLMpics - On what Language Model Pre-training Captures
Alon Talmor, Yanai Elazar, Yoav Goldberg, Jonathan Berant,
