Entity Enhanced BERT Pre-training for Chinese NER
Chen Jia, Yuefeng Shi, Qinrong Yang, Yue Zhang
Information Extraction Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
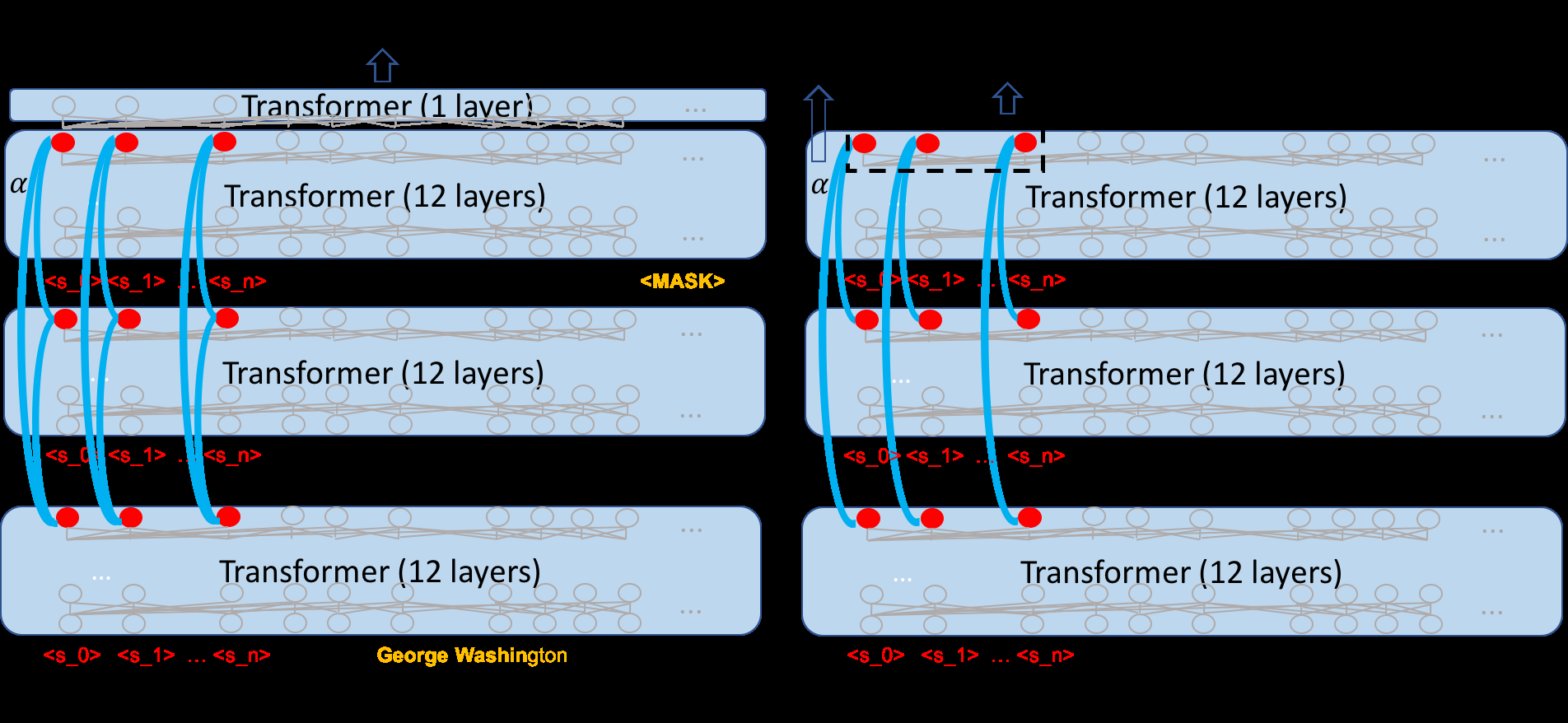
Character-level BERT pre-trained in Chinese suffers a limitation of lacking lexicon information, which shows effectiveness for Chinese NER. To integrate the lexicon into pre-trained LMs for Chinese NER, we investigate a semi-supervised entity enhanced BERT pre-training method. In particular, we first extract an entity lexicon from the relevant raw text using a new-word discovery method. We then integrate the entity information into BERT using Char-Entity-Transformer, which augments the self-attention using a combination of character and entity representations. In addition, an entity classification task helps inject the entity information into model parameters in pre-training. The pre-trained models are used for NER fine-tuning. Experiments on a news dataset and two datasets annotated by ourselves for NER in long-text show that our method is highly effective and achieves the best results.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
BERTweet: A pre-trained language model for English Tweets
Dat Quoc Nguyen, Thanh Vu, Anh Tuan Nguyen,

Coarse-to-Fine Pre-training for Named Entity Recognition
Xue Mengge, Bowen Yu, Zhenyu Zhang, Tingwen Liu, Yue Zhang, Bin Wang,


Cross-Thought for Sentence Encoder Pre-training
Shuohang Wang, Yuwei Fang, Siqi Sun, Zhe Gan, Yu Cheng, Jingjing Liu, Jing Jiang,