Coarse-to-Fine Pre-training for Named Entity Recognition
Xue Mengge, Bowen Yu, Zhenyu Zhang, Tingwen Liu, Yue Zhang, Bin Wang
Information Extraction Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
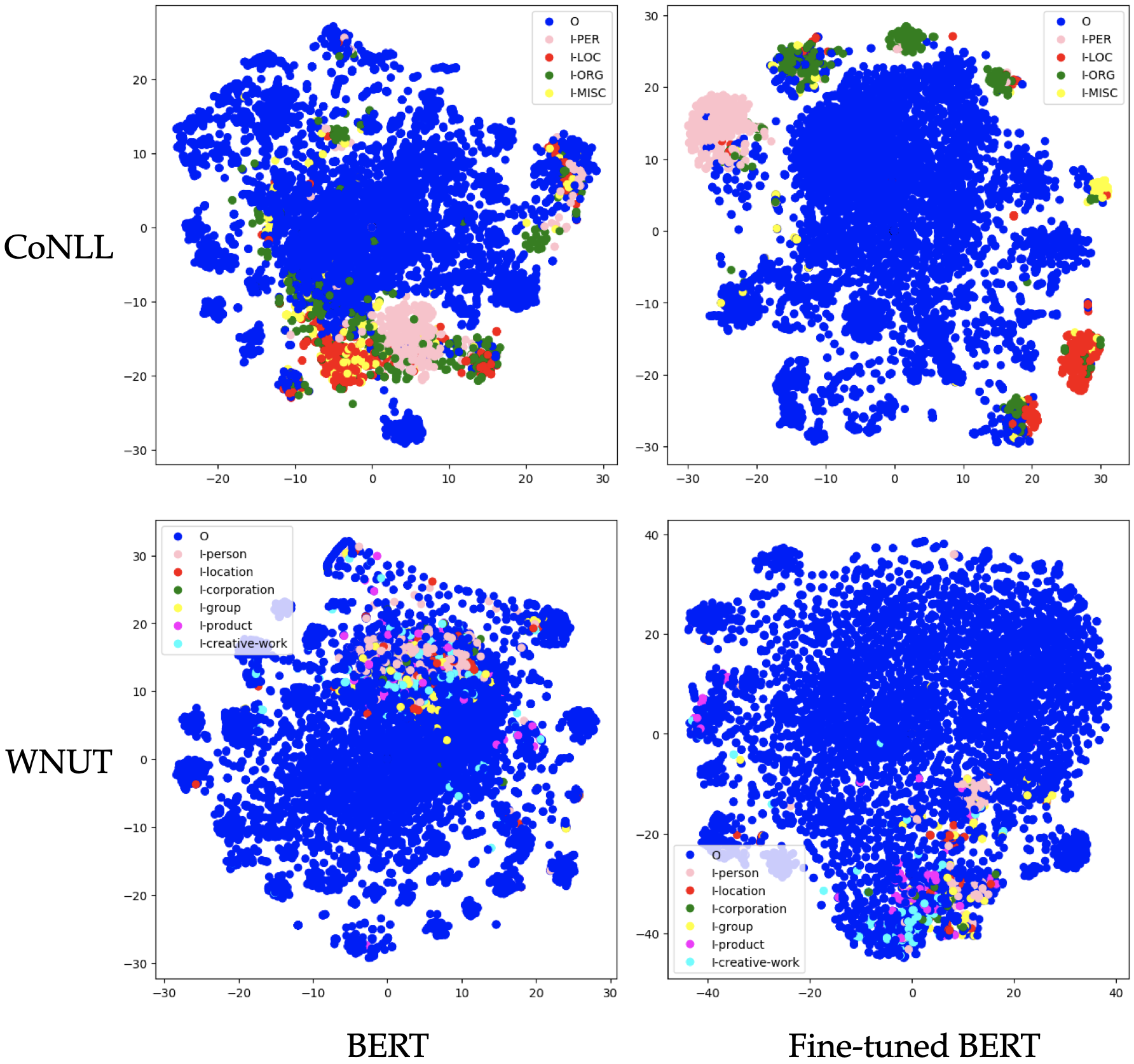
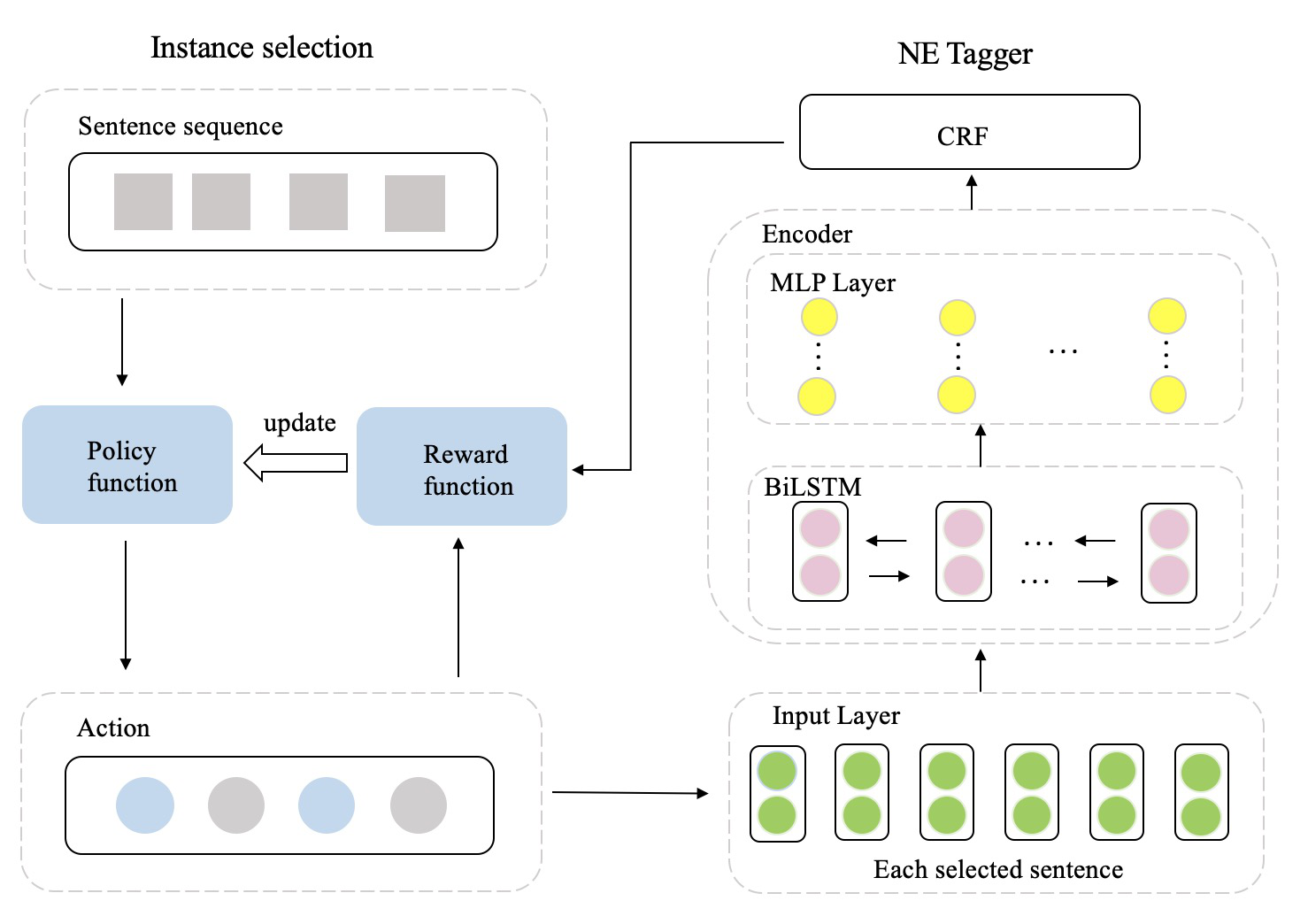
More recently, Named Entity Recognition hasachieved great advances aided by pre-trainingapproaches such as BERT. However, currentpre-training techniques focus on building lan-guage modeling objectives to learn a gen-eral representation, ignoring the named entity-related knowledge. To this end, we proposea NER-specific pre-training framework to in-ject coarse-to-fine automatically mined entityknowledge into pre-trained models. Specifi-cally, we first warm-up the model via an en-tity span identification task by training it withWikipedia anchors, which can be deemed asgeneral-typed entities. Then we leverage thegazetteer-based distant supervision strategy totrain the model extract coarse-grained typedentities. Finally, we devise a self-supervisedauxiliary task to mine the fine-grained namedentity knowledge via clustering.Empiricalstudies on three public NER datasets demon-strate that our framework achieves significantimprovements against several pre-trained base-lines, establishing the new state-of-the-art per-formance on three benchmarks. Besides, weshow that our framework gains promising re-sults without using human-labeled trainingdata, demonstrating its effectiveness in label-few and low-resource scenarios.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers

KGPT: Knowledge-Grounded Pre-Training for Data-to-Text Generation
Wenhu Chen, Yu Su, Xifeng Yan, William Yang Wang,
Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning
Yi Yang, Arzoo Katiyar,