PAIR: Planning and Iterative Refinement in Pre-trained Transformers for Long Text Generation
Xinyu Hua, Lu Wang
Language Generation Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
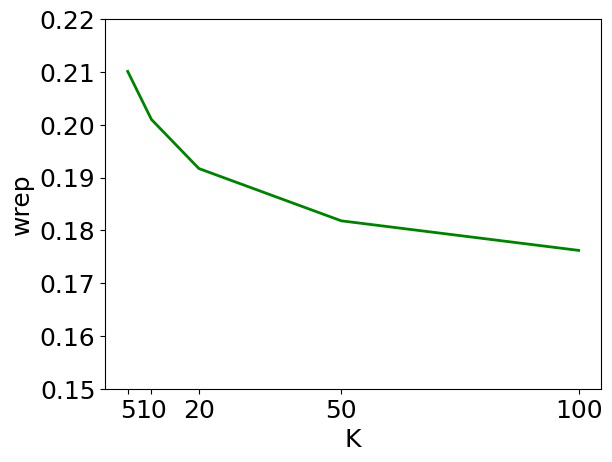
Pre-trained Transformers have enabled impressive breakthroughs in generating long and fluent text, yet their outputs are often “rambling” without coherently arranged content. In this work, we present a novel content-controlled text generation framework, PAIR, with planning and iterative refinement, which is built upon a large model, BART. We first adapt the BERT model to automatically construct the content plans, consisting of keyphrase assignments and their corresponding sentence-level positions. The BART model is employed for generation without modifying its structure. We then propose a refinement algorithm to gradually enhance the generation quality within the sequence-to-sequence framework. Evaluation with automatic metrics shows that adding planning consistently improves the generation quality on three distinct domains, with an average of 20 BLEU points and 12 METEOR points improvements. In addition, human judges rate our system outputs to be more relevant and coherent than comparisons without planning.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Stepwise Extractive Summarization and Planning with Structured Transformers
Shashi Narayan, Joshua Maynez, Jakub Adamek, Daniele Pighin, Blaz Bratanic, Ryan McDonald,
Planning and Generating Natural and Diverse Disfluent Texts as Augmentation for Disfluency Detection
Jingfeng Yang, Diyi Yang, Zhaoran Ma,

Cross Copy Network for Dialogue Generation
Changzhen Ji, Xin Zhou, Yating Zhang, Xiaozhong Liu, Changlong Sun, Conghui Zhu, Tiejun Zhao,