ETC: Encoding Long and Structured Inputs in Transformers
Joshua Ainslie, Santiago Ontanon, Chris Alberti, Vaclav Cvicek, Zachary Fisher, Philip Pham, Anirudh Ravula, Sumit Sanghai, Qifan Wang, Li Yang
Machine Learning for NLP Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
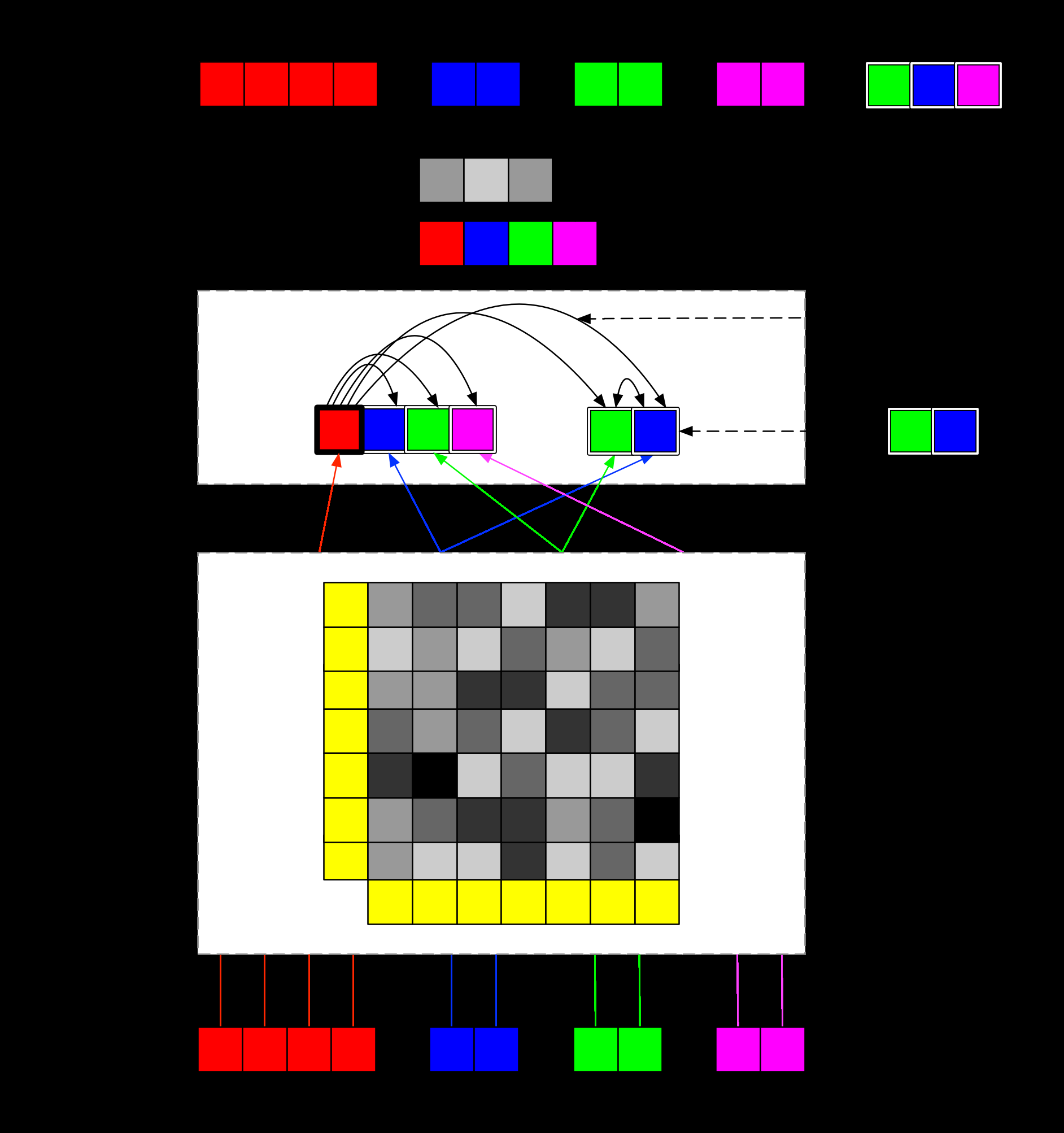
Transformer models have advanced the state of the art in many Natural Language Processing (NLP) tasks. In this paper, we present a new Transformer architecture, "Extended Transformer Construction" (ETC), that addresses two key challenges of standard Transformer architectures, namely scaling input length and encoding structured inputs. To scale attention to longer inputs, we introduce a novel global-local attention mechanism between global tokens and regular input tokens. We also show that combining global-local attention with relative position encodings and a "Contrastive Predictive Coding" (CPC) pre-training objective allows ETC to encode structured inputs. We achieve state-of-the-art results on four natural language datasets requiring long and/or structured inputs.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Long-Short Term Masking Transformer: A Simple but Effective Baseline for Document-level Neural Machine Translation
Pei Zhang, Boxing Chen, Niyu Ge, Kai Fan,

Cross-Thought for Sentence Encoder Pre-training
Shuohang Wang, Yuwei Fang, Siqi Sun, Zhe Gan, Yu Cheng, Jingjing Liu, Jing Jiang,

Stepwise Extractive Summarization and Planning with Structured Transformers
Shashi Narayan, Joshua Maynez, Jakub Adamek, Daniele Pighin, Blaz Bratanic, Ryan McDonald,