TORQUE: A Reading Comprehension Dataset of Temporal Ordering Questions
Qiang Ning, Hao Wu, Rujun Han, Nanyun Peng, Matt Gardner, Dan Roth
Question Answering Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
A critical part of reading is being able to understand the temporal relationships between events described in a passage of text, even when those relationships are not explicitly stated. However, current machine reading comprehension benchmarks have practically no questions that test temporal phenomena, so systems trained on these benchmarks have no capacity to answer questions such as ``what happened before/after [some event]?'' We introduce TORQUE, a new English reading comprehension benchmark built on 3.2k news snippets with 21k human-generated questions querying temporal relationships. Results show that RoBERTa-large achieves an exact-match score of 51% on the test set of TORQUE, about 30% behind human performance.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Inquisitive Question Generation for High Level Text Comprehension
Wei-Jen Ko, Te-yuan Chen, Yiyan Huang, Greg Durrett, Junyi Jessy Li,
Reasoning about Goals, Steps, and Temporal Ordering with WikiHow
Li Zhang, Qing Lyu, Chris Callison-Burch,

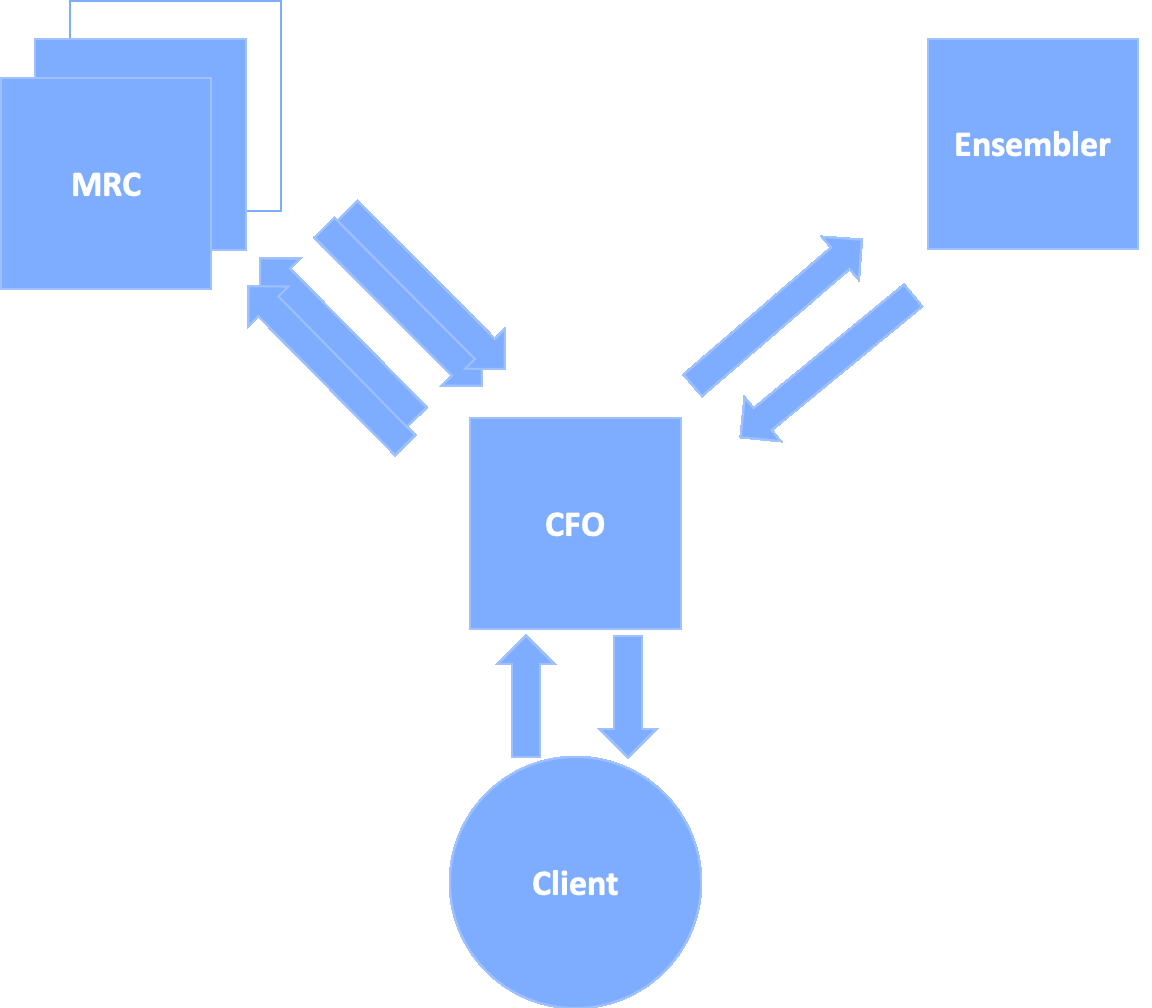
ARES: A Reading Comprehension Ensembling Service
Anthony Ferritto, Lin Pan, Rishav Chakravarti, Salim Roukos, Radu Florian, J William Murdock, Avi Sil,
A Simple and Effective Model for Answering Multi-span Questions
Elad Segal, Avia Efrat, Mor Shoham, Amir Globerson, Jonathan Berant,
