Bootstrapped Q-learning with Context Relevant Observation Pruning to Generalize in Text-based Games
Subhajit Chaudhury, Daiki Kimura, Kartik Talamadupula, Michiaki Tatsubori, Asim Munawar, Ryuki Tachibana
Machine Learning for NLP Short Paper

You can open the pre-recorded video in a separate window.
Abstract:
We show that Reinforcement Learning (RL) methods for solving Text-Based Games (TBGs) often fail to generalize on unseen games, especially in small data regimes. To address this issue, we propose Context Relevant Episodic State Truncation (CREST) for irrelevant token removal in observation text for improved generalization. Our method first trains a base model using Q-learning, which typically overfits the training games. The base model's action token distribution is used to perform observation pruning that removes irrelevant tokens. A second bootstrapped model is then retrained on the pruned observation text. Our bootstrapped agent shows improved generalization in solving unseen TextWorld games, using 10x-20x fewer training games compared to previous state-of-the-art (SOTA) methods despite requiring fewer number of training episodes.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
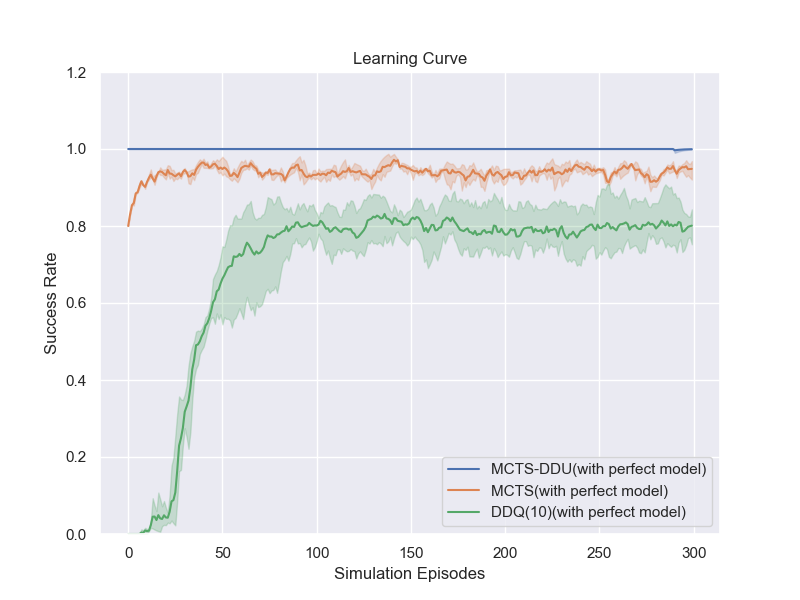
Task-Completion Dialogue Policy Learning via Monte Carlo Tree Search with Dueling Network
Sihan Wang, Kaijie Zhou, Kunfeng Lai, Jianping Shen,
Improving Text Generation with Student-Forcing Optimal Transport
Jianqiao Li, Chunyuan Li, Guoyin Wang, Hao Fu, Yuhchen Lin, Liqun Chen, Yizhe Zhang, Chenyang Tao, Ruiyi Zhang, Wenlin Wang, Dinghan Shen, Qian Yang, Lawrence Carin,

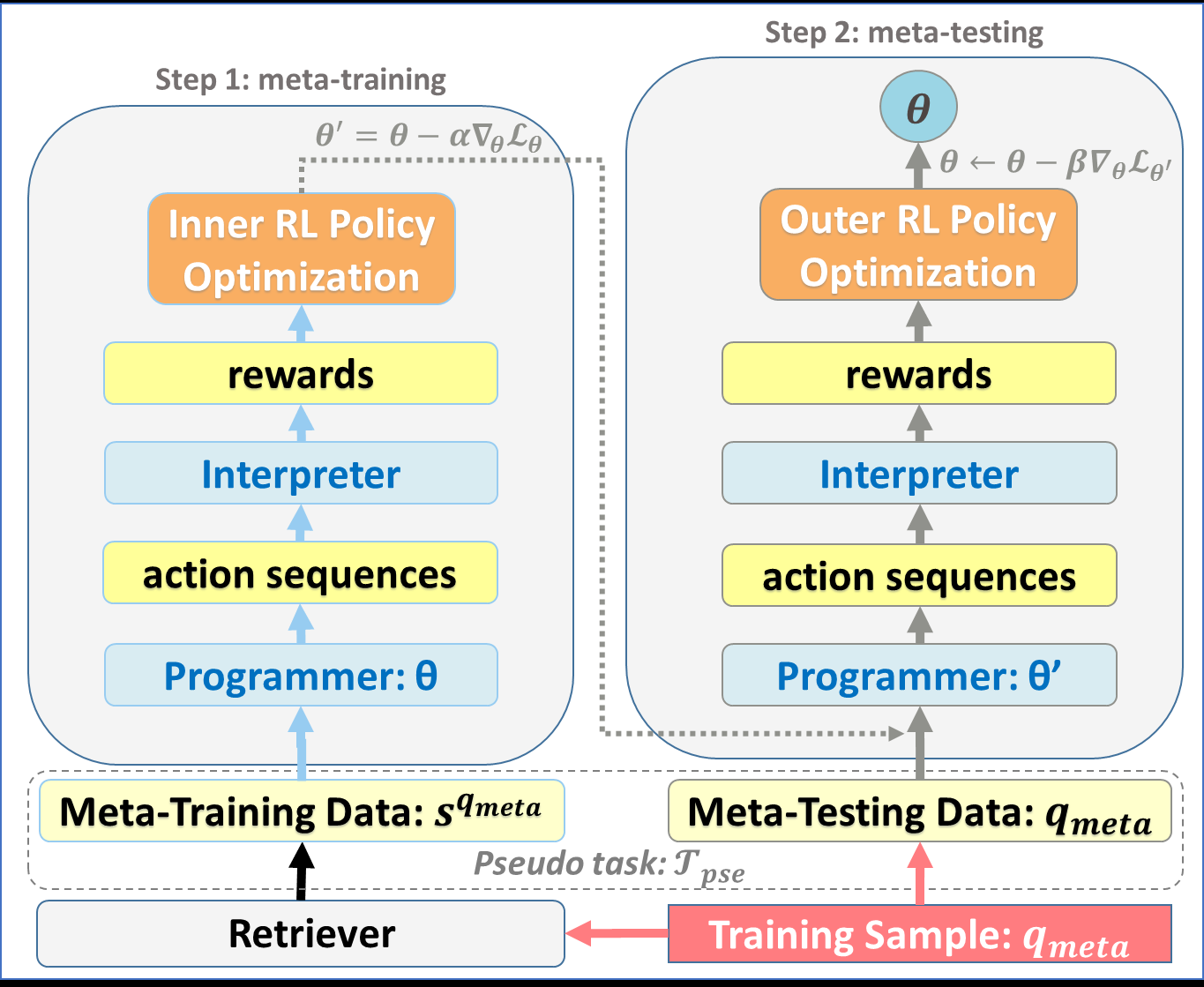
Few-Shot Complex Knowledge Base Question Answering via Meta Reinforcement Learning
Yuncheng Hua, Yuan-Fang Li, Gholamreza Haffari, Guilin Qi, Tongtong Wu,
Supervised Seeded Iterated Learning for Interactive Language Learning
Yuchen Lu, Soumye Singhal, Florian Strub, Olivier Pietquin, Aaron Courville,