Multi-View Sequence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization
Jiaao Chen, Diyi Yang
Summarization Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
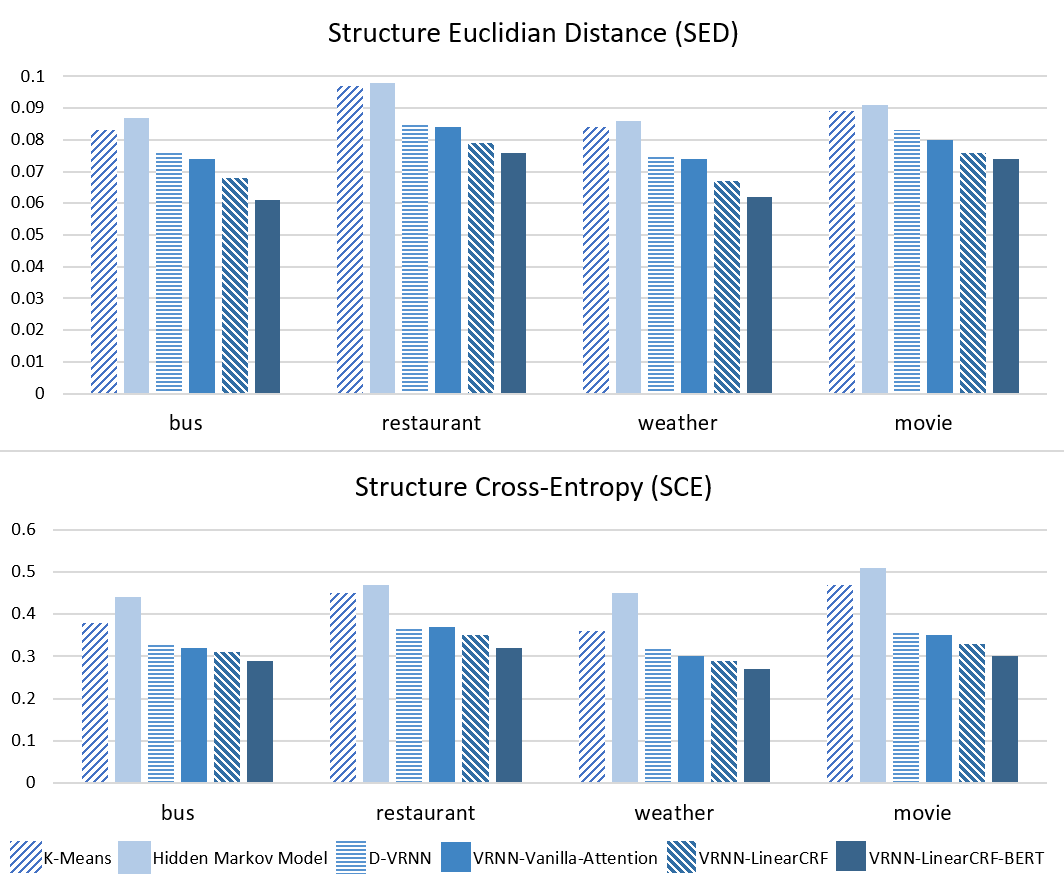
Text summarization is one of the most challenging and interesting problems in NLP. Although much attention has been paid to summarizing structured text like news reports or encyclopedia articles, summarizing conversations---an essential part of human-human/machine interaction where most important pieces of information are scattered across various utterances of different speakers---remains relatively under-investigated. This work proposes a multi-view sequence-to-sequence model by first extracting conversational structures of unstructured daily chats from different views to represent conversations and then utilizing a multi-view decoder to incorporate different views to generate dialogue summaries. Experiments on a large-scale dialogue summarization corpus demonstrated that our methods significantly outperformed previous state-of-the-art models via both automatic evaluations and human judgment. We also discussed specific challenges that current approaches faced with this task. We have publicly released our code at https://github.com/GT-SALT/Multi-View-Seq2Seq.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Multi-turn Response Selection using Dialogue Dependency Relations
Qi Jia, Yizhu Liu, Siyu Ren, Kenny Zhu, Haifeng Tang,

RiSAWOZ: A Large-Scale Multi-Domain Wizard-of-Oz Dataset with Rich Semantic Annotations for Task-Oriented Dialogue Modeling
Jun Quan, Shian Zhang, Qian Cao, Zizhong Li, Deyi Xiong,

Learning a Simple and Effective Model for Multi-turn Response Generation with Auxiliary Tasks
Yufan Zhao, Can Xu, Wei Wu,
Structured Attention for Unsupervised Dialogue Structure Induction
Liang Qiu, Yizhou Zhao, Weiyan Shi, Yuan Liang, Feng Shi, Tao Yuan, Zhou Yu, Song-Chun Zhu,