An information theoretic view on selecting linguistic probes
Zining Zhu, Frank Rudzicz
Interpretability and Analysis of Models for NLP Short Paper

You can open the pre-recorded video in a separate window.
Abstract:
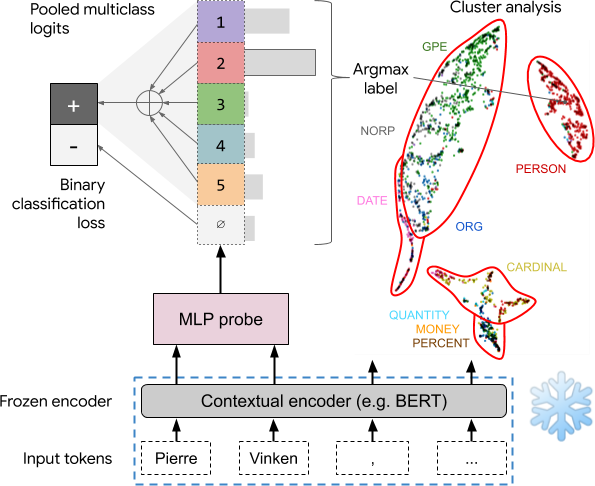
There is increasing interest in assessing the linguistic knowledge encoded in neural representations. A popular approach is to attach a diagnostic classifier -- or ''probe'' -- to perform supervised classification from internal representations. However, how to select a good probe is in debate. Hewitt and Liang (2019) showed that a high performance on diagnostic classification itself is insufficient, because it can be attributed to either ''the representation being rich in knowledge'', or ''the probe learning the task'', which Pimentel et al. (2020) challenged. We show this dichotomy is valid information-theoretically. In addition, we find that the ''good probe'' criteria proposed by the two papers, *selectivity* (Hewitt and Liang, 2019) and *information gain* (Pimentel et al., 2020), are equivalent -- the errors of their approaches are identical (modulo irrelevant terms). Empirically, these two selection criteria lead to results that highly agree with each other.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Intrinsic Probing through Dimension Selection
Lucas Torroba Hennigen, Adina Williams, Ryan Cotterell,

A matter of framing: The impact of linguistic formalism on probing results
Ilia Kuznetsov, Iryna Gurevych,

Investigating representations of verb bias in neural language models
Robert Hawkins, Takateru Yamakoshi, Thomas Griffiths, Adele Goldberg,

Asking without Telling: Exploring Latent Ontologies in Contextual Representations
Julian Michael, Jan A. Botha, Ian Tenney,