Multistage Fusion with Forget Gate for Multimodal Summarization in Open-Domain Videos
Nayu Liu, Xian Sun, Hongfeng Yu, Wenkai Zhang, Guangluan Xu
Summarization Long Paper

Abstract:
Multimodal summarization for open-domain videos is an emerging task, aiming to generate a summary from multisource information (video, audio, transcript). Despite the success of recent multiencoder-decoder frameworks on this task, existing methods lack fine-grained multimodality interactions of multisource inputs. Besides, unlike other multimodal tasks, this task has longer multimodal sequences with more redundancy and noise. To address these two issues, we propose a multistage fusion network with the fusion forget gate module, which builds upon this approach by modeling fine-grained interactions between the modalities through a multistep fusion schema and controlling the flow of redundant information between multimodal long sequences via a forgetting module. Experimental results on the How2 dataset show that our proposed model achieves a new state-of-the-art performance. Comprehensive analysis empirically verifies the effectiveness of our fusion schema and forgetting module on multiple encoder-decoder architectures. Specially, when using high noise ASR transcripts (WER>30%), our model still achieves performance close to the ground-truth transcript model, which reduces manual annotation cost.
Connected Papers in EMNLP2020
Similar Papers
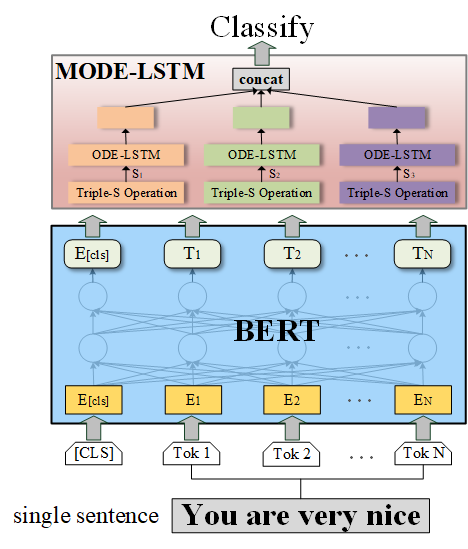
MODE-LSTM: A Parameter-efficient Recurrent Network with Multi-Scale for Sentence Classification
Qianli Ma, Zhenxi Lin, Jiangyue Yan, Zipeng Chen, Liuhong Yu,
HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training
Linjie Li, Yen-Chun Chen, Yu Cheng, Zhe Gan, Licheng Yu, Jingjing Liu,
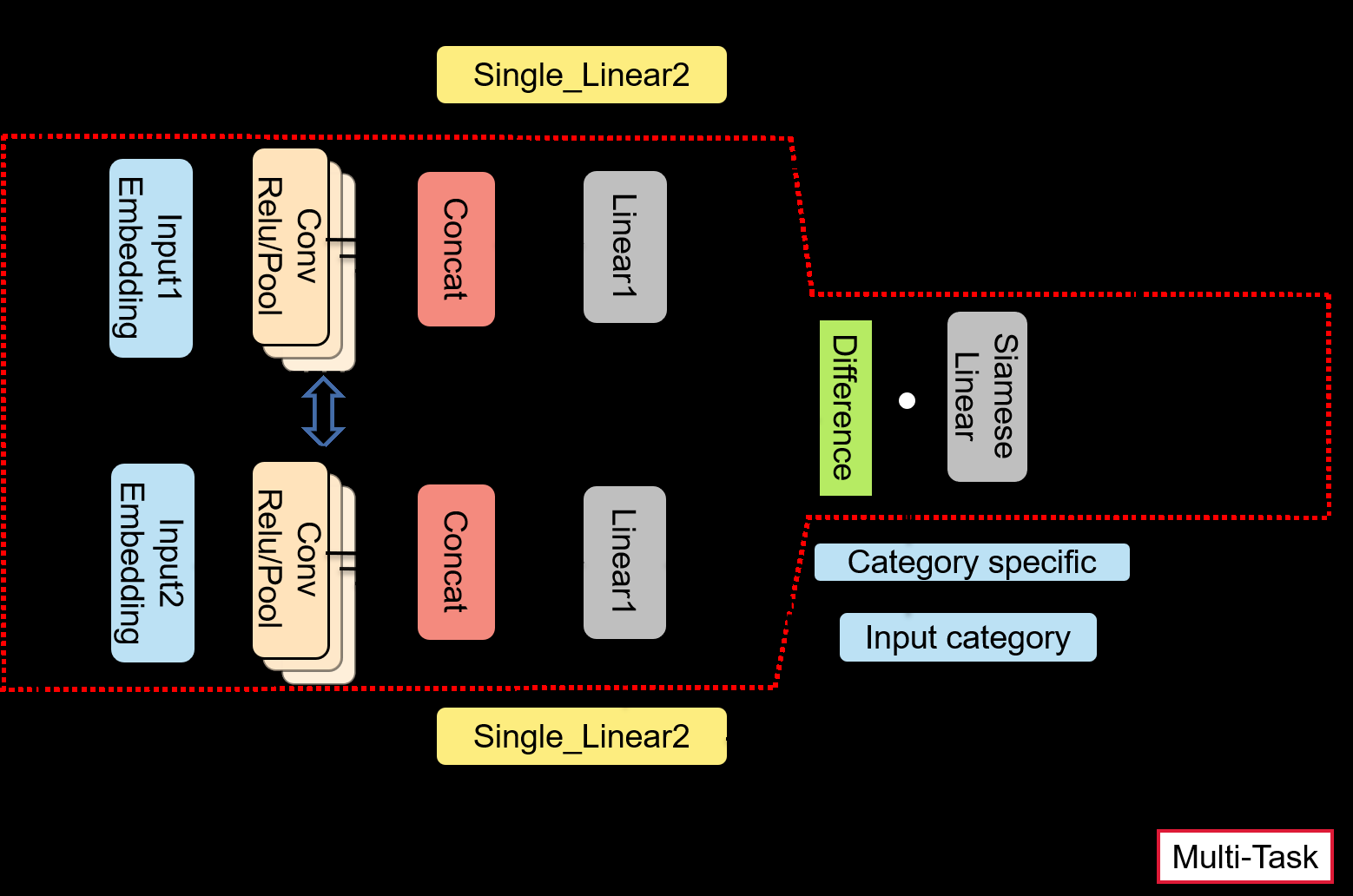
HSCNN: A Hybrid-Siamese Convolutional Neural Network for Extremely Imbalanced Multi-label Text Classification
Wenshuo Yang, Jiyi Li, Fumiyo Fukumoto, Yanming Ye,
Q-learning with Language Model for Edit-based Unsupervised Summarization
Ryosuke Kohita, Akifumi Wachi, Yang Zhao, Ryuki Tachibana,
