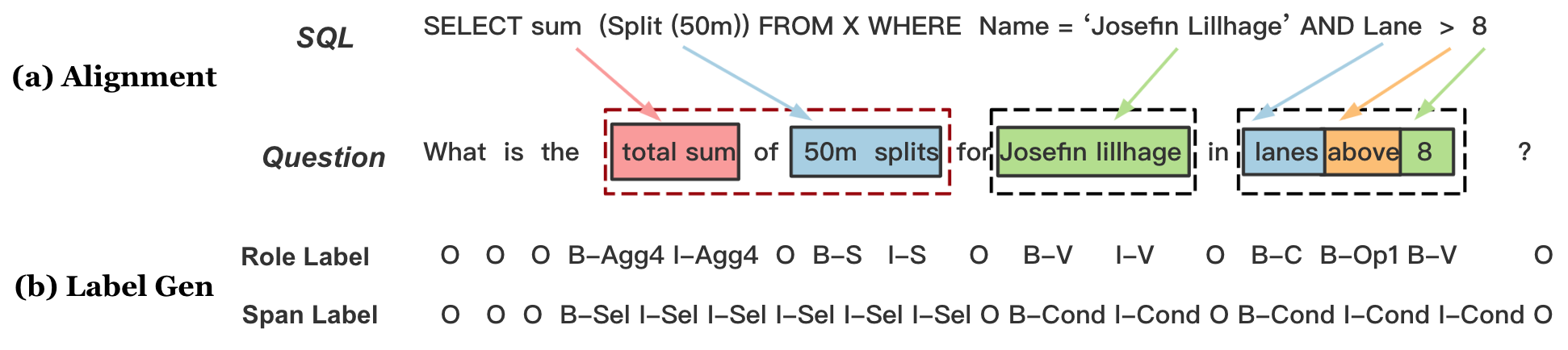
DuSQL: A Large-Scale and Pragmatic Chinese Text-to-SQL Dataset
Lijie Wang, Ao Zhang, Kun Wu, Ke Sun, Zhenghua Li, Hua Wu, Min Zhang, Haifeng Wang
Semantics: Sentence-level Semantics, Textual Inference and Other areas Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
Due to the lack of labeled data, previous research on text-to-SQL parsing mainly focuses on English. Representative English datasets include ATIS, WikiSQL, Spider, etc. This paper presents DuSQL, a larges-scale and pragmatic Chinese dataset for the cross-domain text-to-SQL task, containing 200 databases, 813 tables, and 23,797 question/SQL pairs. Our new dataset has three major characteristics. First, by manually analyzing questions from several representative applications, we try to figure out the true distribution of SQL queries in real-life needs. Second, DuSQL contains a considerable proportion of SQL queries involving row or column calculations, motivated by our analysis on the SQL query distributions. Finally, we adopt an effective data construction framework via human-computer collaboration. The basic idea is automatically generating SQL queries based on the SQL grammar and constrained by the given database. This paper describes in detail the construction process and data statistics of DuSQL. Moreover, we present and compare performance of several open-source text-to-SQL parsers with minor modification to accommodate Chinese, including a simple yet effective extension to IRNet for handling calculation SQL queries.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
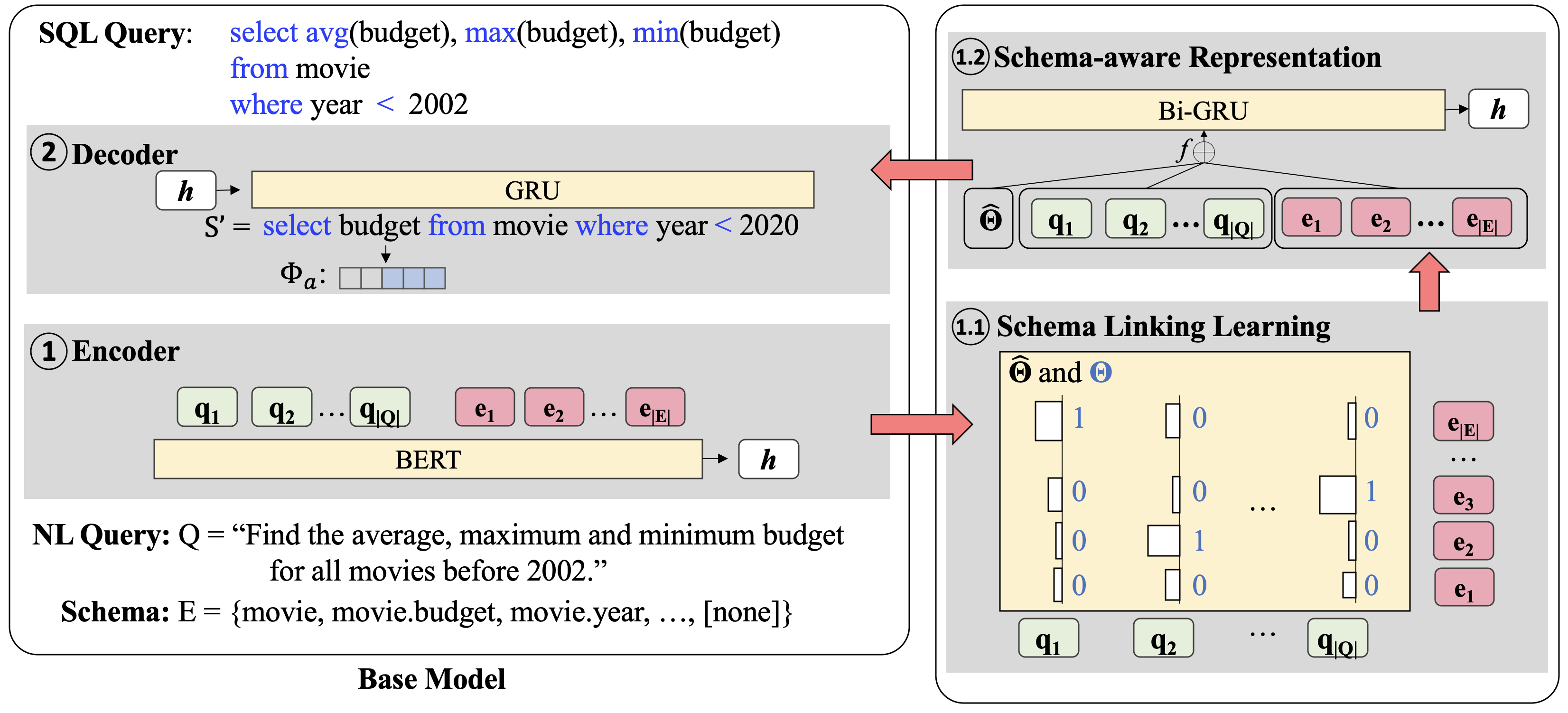
Re-examining the Role of Schema Linking in Text-to-SQL
Wenqiang Lei, Weixin Wang, Zhixin Ma, Tian Gan, Wei Lu, Min-Yen Kan, Tat-Seng Chua,
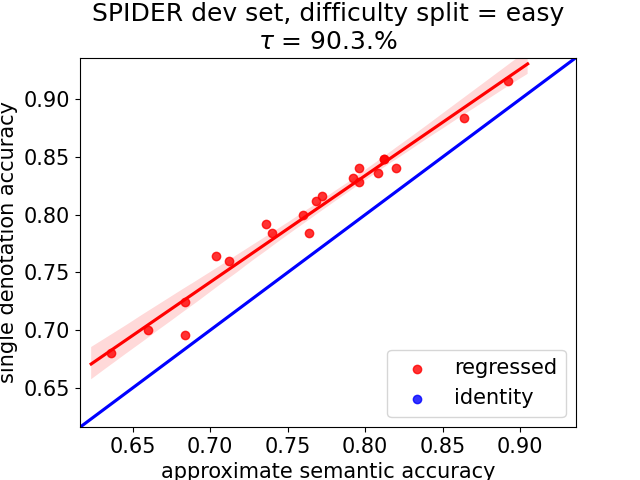
Mention Extraction and Linking for SQL Query Generation
Jianqiang Ma, Zeyu Yan, Shuai Pang, Yang Zhang, Jianping Shen,