What Do Position Embeddings Learn? An Empirical Study of Pre-Trained Language Model Positional Encoding
Yu-An Wang, Yun-Nung Chen
Interpretability and Analysis of Models for NLP Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
In recent years, pre-trained Transformers have dominated the majority of NLP benchmark tasks. Many variants of pre-trained Transformers have kept breaking out, and most focus on designing different pre-training objectives or variants of self-attention. Embedding the position information in the self-attention mechanism is also an indispensable factor in Transformers however is often discussed at will. Hence, we carry out an empirical study on position embedding of mainstream pre-trained Transformers mainly focusing on two questions: 1) Do position embeddings really learn the meaning of positions? 2) How do these different learned position embeddings affect Transformers for NLP tasks? This paper focuses on providing a new insight of pre-trained position embeddings by feature-level analysis and empirical experiments on most of iconic NLP tasks. It is believed that our experimental results can guide the future works to choose the suitable positional encoding function for specific tasks given the application property.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
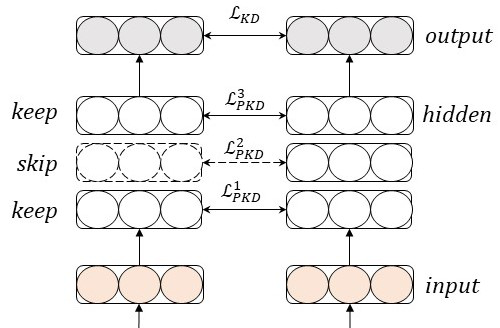
Why Skip If You Can Combine: A Simple Knowledge Distillation Technique for Intermediate Layers
Yimeng Wu, Peyman Passban, Mehdi Rezagholizadeh, Qun Liu,
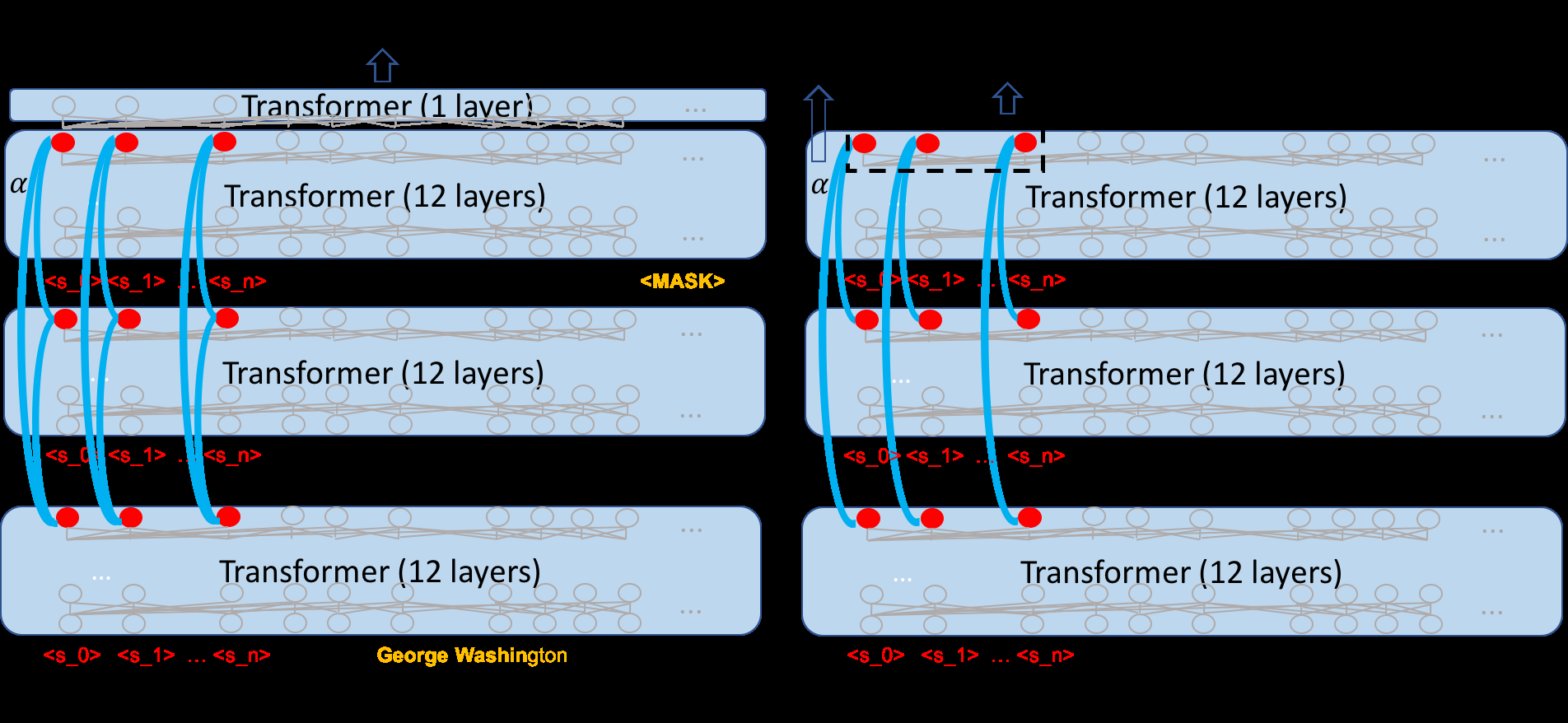
Syntactic Structure Distillation Pretraining for Bidirectional Encoders
Adhiguna Kuncoro, Lingpeng Kong, Daniel Fried, Dani Yogatama, Laura Rimell, Chris Dyer, Phil Blunsom,

Cross-Thought for Sentence Encoder Pre-training
Shuohang Wang, Yuwei Fang, Siqi Sun, Zhe Gan, Yu Cheng, Jingjing Liu, Jing Jiang,
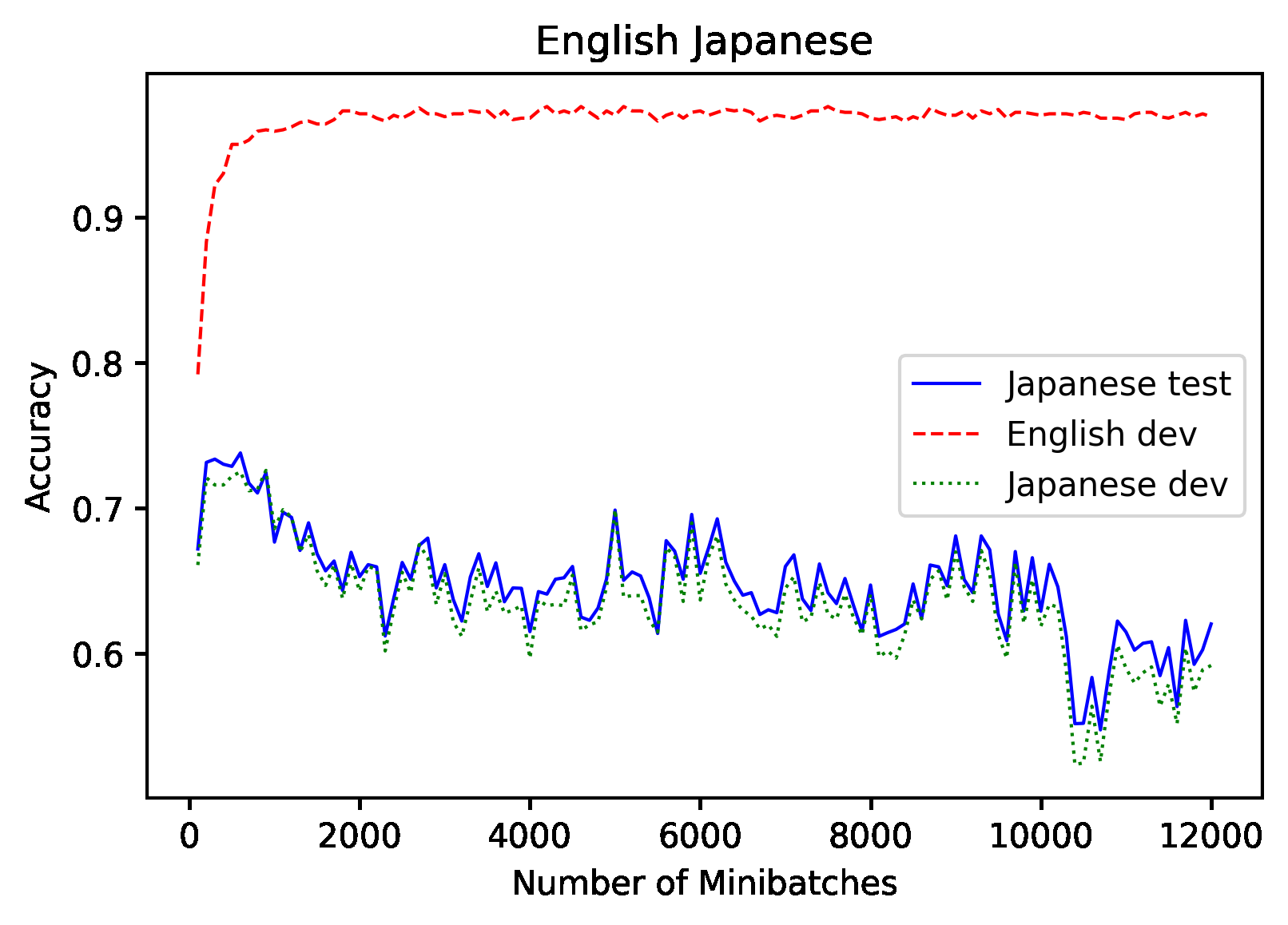
Don't Use English Dev: On the Zero-Shot Cross-Lingual Evaluation of Contextual Embeddings
Phillip Keung, Yichao Lu, Julian Salazar, Vikas Bhardwaj,