TernaryBERT: Distillation-aware Ultra-low Bit BERT
Wei Zhang, Lu Hou, Yichun Yin, Lifeng Shang, Xiao Chen, Xin Jiang, Qun Liu
Machine Learning for NLP Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
Transformer-based pre-training models like BERT have achieved remarkable performance in many natural language processing tasks. However, these models are both computation and memory expensive, hindering their deployment to resource-constrained devices. In this work, we propose TernaryBERT, which ternarizes the weights in a fine-tuned BERT model. Specifically, we use both approximation-based and loss-aware ternarization methods and empirically investigate the ternarization granularity of different parts of BERT. Moreover, to reduce the accuracy degradation caused by lower capacity of low bits, we leverage the knowledge distillation technique in the training process. Experiments on the GLUE benchmark and SQuAD show that our proposed TernaryBERT outperforms the other BERT quantization methods, and even achieves comparable performance as the full-precision model while being 14.9x smaller.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Analyzing Redundancy in Pretrained Transformer Models
Fahim Dalvi, Hassan Sajjad, Nadir Durrani, Yonatan Belinkov,
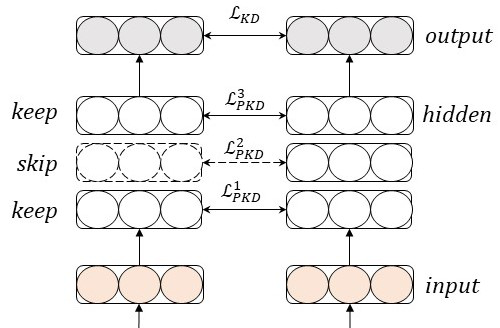
Why Skip If You Can Combine: A Simple Knowledge Distillation Technique for Intermediate Layers
Yimeng Wu, Peyman Passban, Mehdi Rezagholizadeh, Qun Liu,
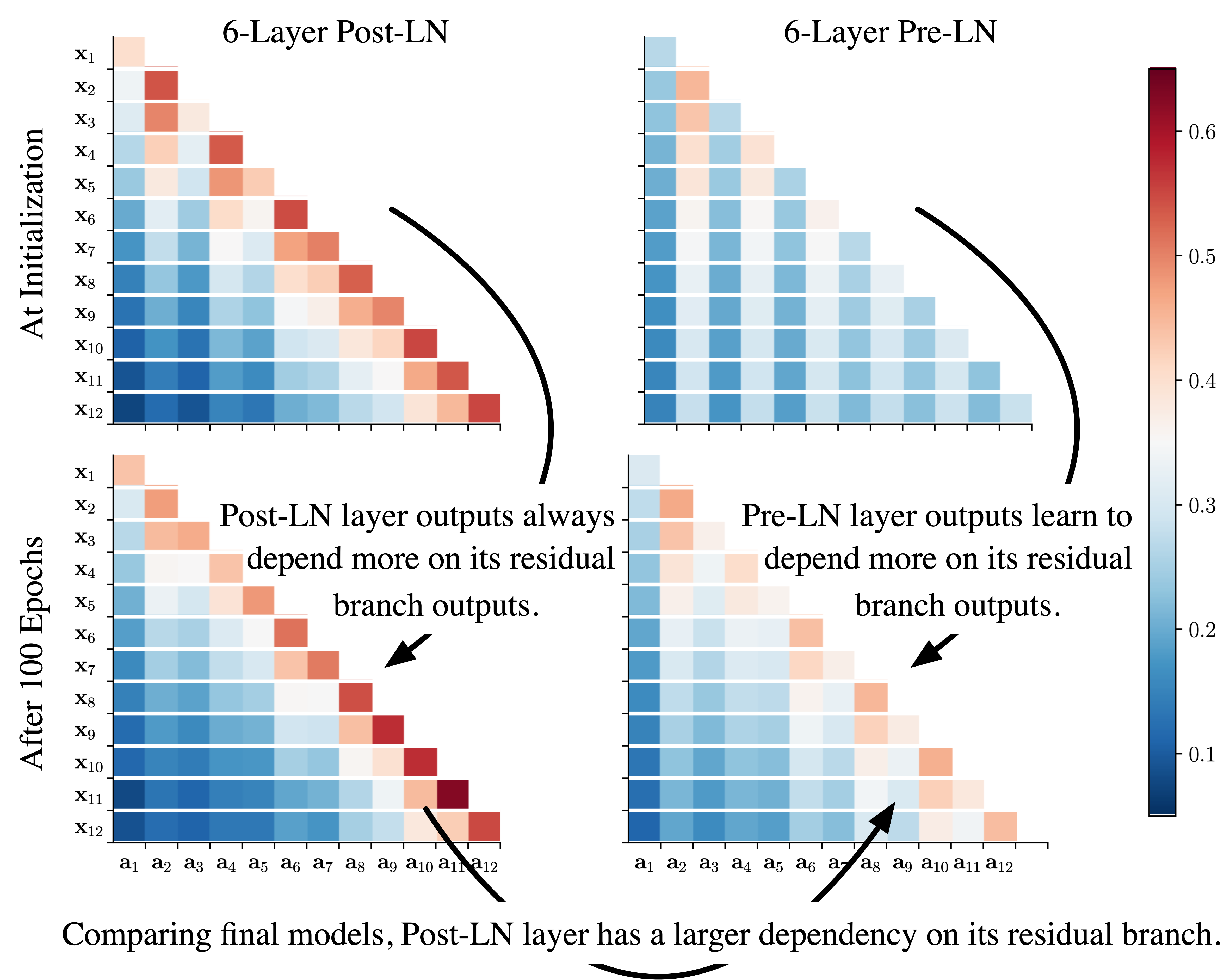
Understanding the Difficulty of Training Transformers
Liyuan Liu, Xiaodong Liu, Jianfeng Gao, Weizhu Chen, Jiawei Han,
Contrastive Distillation on Intermediate Representations for Language Model Compression
Siqi Sun, Zhe Gan, Yuwei Fang, Yu Cheng, Shuohang Wang, Jingjing Liu,
