CCAligned: A Massive Collection of Cross-Lingual Web-Document Pairs
Ahmed El-Kishky, Vishrav Chaudhary, Francisco Guzmán, Philipp Koehn
Machine Translation and Multilinguality Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
Cross-lingual document alignment aims to identify pairs of documents in two distinct languages that are of comparable content or translations of each other. In this paper, we exploit the signals embedded in URLs to label web documents at scale with an average precision of 94.5% across different language pairs. We mine sixty-eight snapshots of the Common Crawl corpus and identify web document pairs that are translations of each other. We release a new web dataset consisting of over 392 million URL pairs from Common Crawl covering documents in 8144 language pairs of which 137 pairs include English. In addition to curating this massive dataset, we introduce baseline methods that leverage cross-lingual representations to identify aligned documents based on their textual content. Finally, we demonstrate the value of this parallel documents dataset through a downstream task of mining parallel sentences and measuring the quality of machine translations from models trained on this mined data. Our objective in releasing this dataset is to foster new research in cross-lingual NLP across a variety of low, medium, and high-resource languages.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers

Design Challenges in Low-resource Cross-lingual Entity Linking
Xingyu Fu, Weijia Shi, Xiaodong Yu, Zian Zhao, Dan Roth,
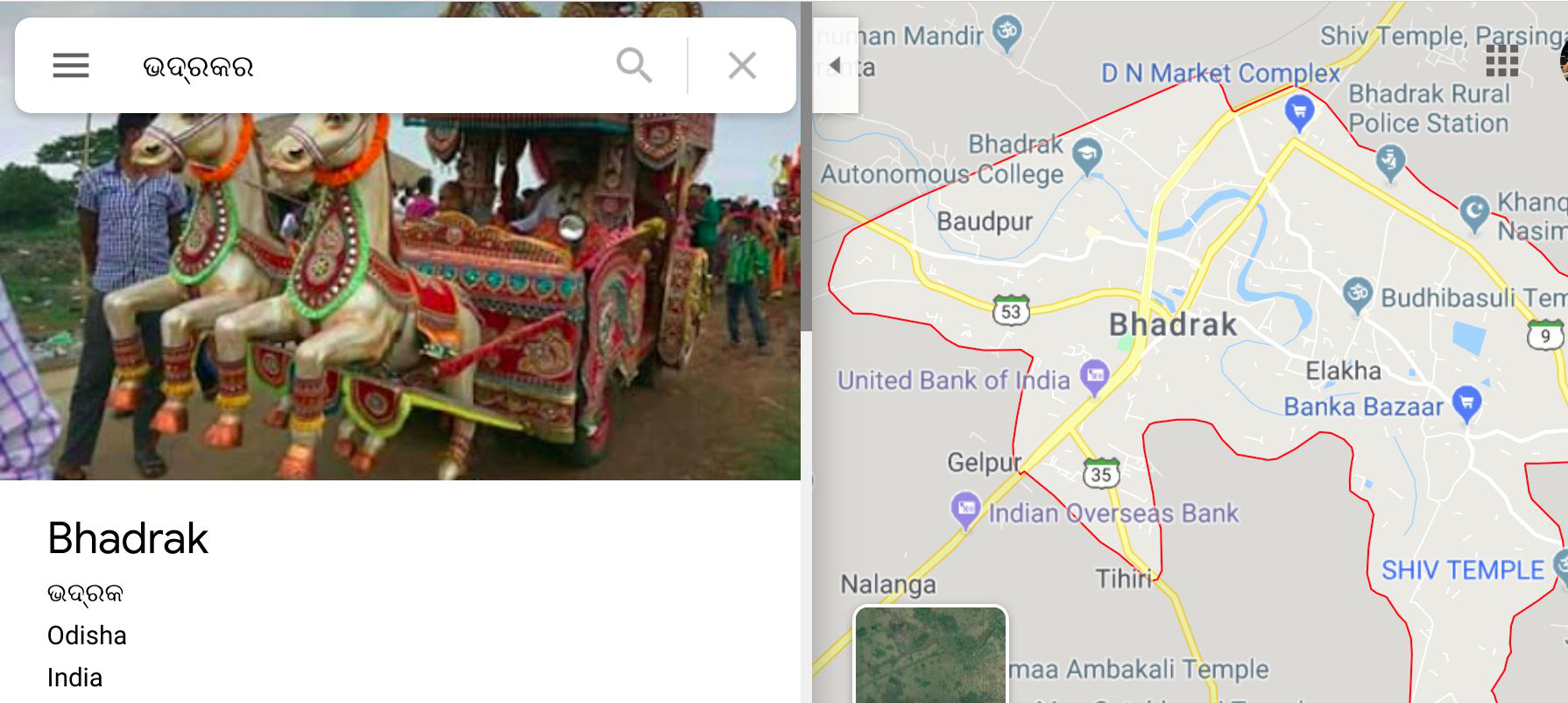
The Secret is in the Spectra: Predicting Cross-lingual Task Performance with Spectral Similarity Measures
Haim Dubossarsky, Ivan Vulić, Roi Reichart, Anna Korhonen,
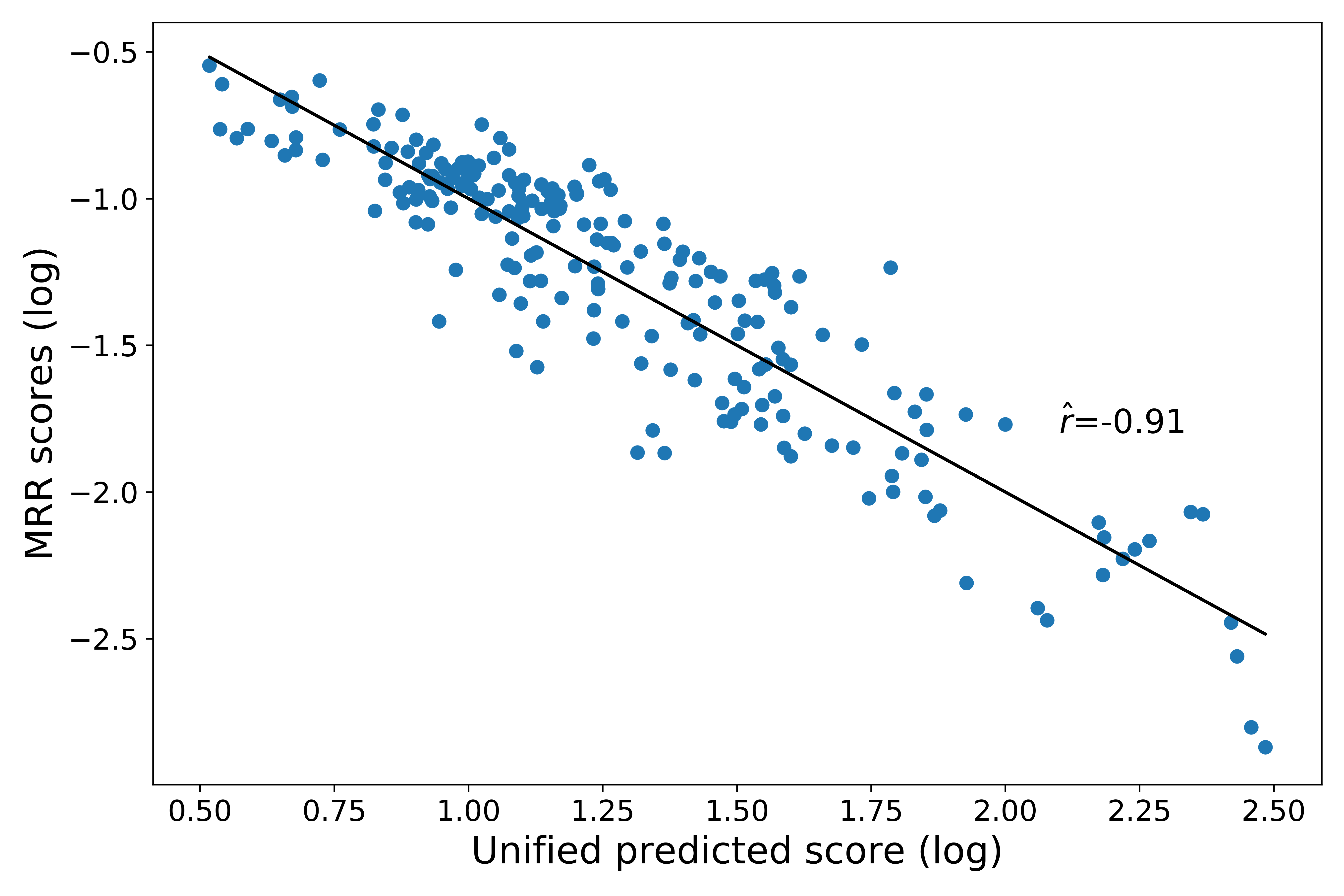
Unsupervised Cross-Lingual Part-of-Speech Tagging for Truly Low-Resource Scenarios
Ramy Eskander, Smaranda Muresan, Michael Collins,