OCR Post Correction for Endangered Language Texts
Shruti Rijhwani, Antonios Anastasopoulos, Graham Neubig
Machine Translation and Multilinguality Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
There is little to no data available to build natural language processing models for most endangered languages. However, textual data in these languages often exists in formats that are not machine-readable, such as paper books and scanned images. In this work, we address the task of extracting text from these resources. We create a benchmark dataset of transcriptions for scanned books in three critically endangered languages and present a systematic analysis of how general-purpose OCR tools are not robust to the data-scarce setting of endangered languages. We develop an OCR post-correction method tailored to ease training in this data-scarce setting, reducing the recognition error rate by 34% on average across the three languages.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
IGT2P: From Interlinear Glossed Texts to Paradigms
Sarah Moeller, Ling Liu, Changbing Yang, Katharina Kann, Mans Hulden,

The Thieves on Sesame Street are Polyglots - Extracting Multilingual Models from Monolingual APIs
Nitish Shirish Keskar, Bryan McCann, Caiming Xiong, Richard Socher,

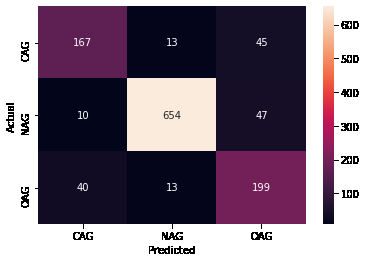
Multilingual Offensive Language Identification with Cross-lingual Embeddings
Tharindu Ranasinghe, Marcos Zampieri,