Small but Mighty: New Benchmarks for Split and Rephrase
Li Zhang, Huaiyu Zhu, Siddhartha Brahma, Yunyao Li
Semantics: Sentence-level Semantics, Textual Inference and Other areas Short Paper

You can open the pre-recorded video in a separate window.
Abstract:
Split and Rephrase is a text simplification task of rewriting a complex sentence into simpler ones. As a relatively new task, it is paramount to ensure the soundness of its evaluation benchmark and metric. We find that the widely used benchmark dataset universally contains easily exploitable syntactic cues caused by its automatic generation process. Taking advantage of such cues, we show that even a simple rule-based model can perform on par with the state-of-the-art model. To remedy such limitations, we collect and release two crowdsourced benchmark datasets. We not only make sure that they contain significantly more diverse syntax, but also carefully control for their quality according to a well-defined set of criteria. While no satisfactory automatic metric exists, we apply fine-grained manual evaluation based on these criteria using crowdsourcing, showing that our datasets better represent the task and are significantly more challenging for the models.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
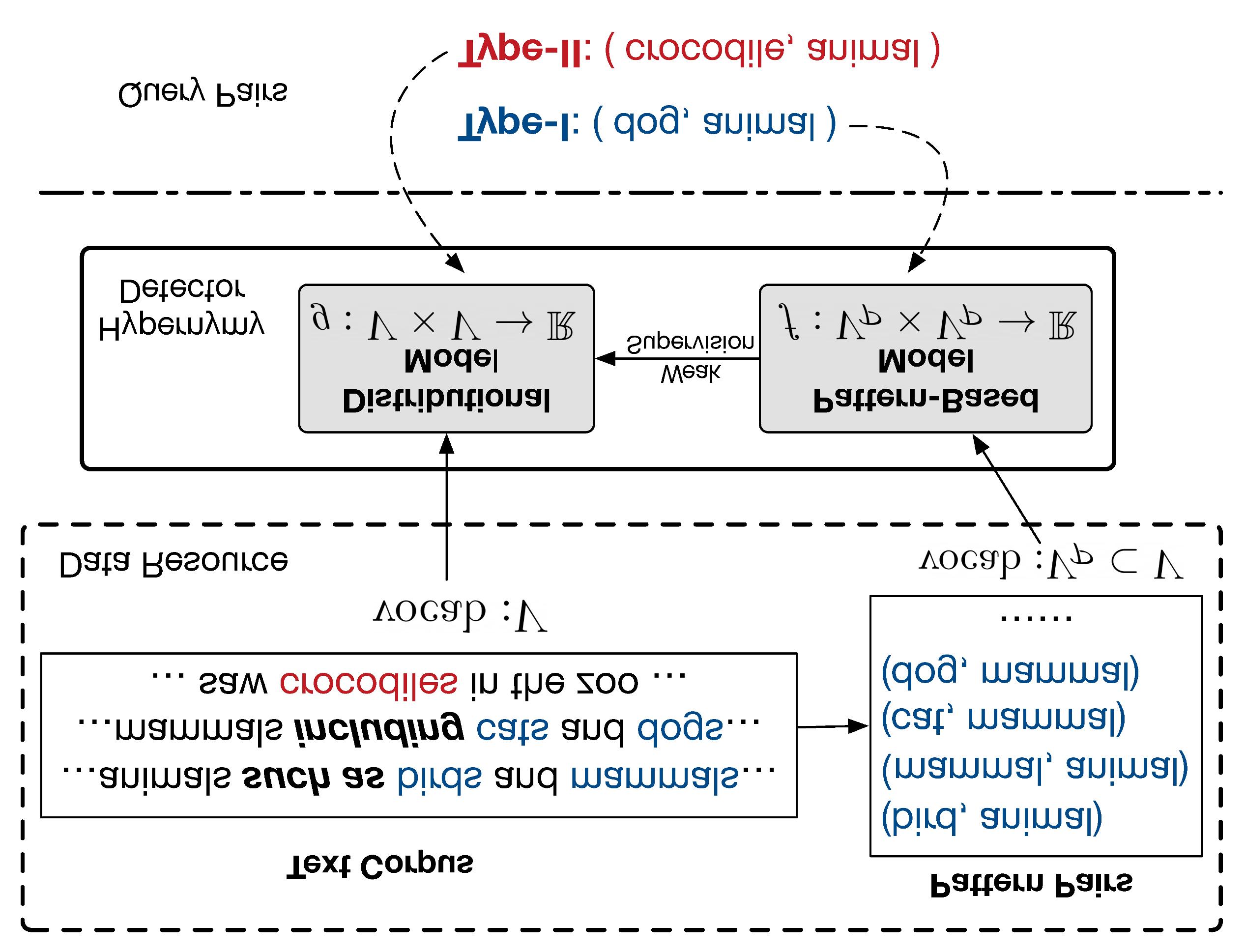
When Hearst Is not Enough: Improving Hypernymy Detection from Corpus with Distributional Models
Changlong Yu, Jialong Han, Peifeng Wang, Yangqiu Song, Hongming Zhang, Wilfred Ng, Shuming Shi,

Sound Natural: Content Rephrasing in Dialog Systems
Arash Einolghozati, Anchit Gupta, Keith Diedrick, Sonal Gupta,
