A Simple Yet Strong Pipeline for HotpotQA
Dirk Groeneveld, Tushar Khot, Mausam, Ashish Sabharwal
Question Answering Short Paper

You can open the pre-recorded video in a separate window.
Abstract:
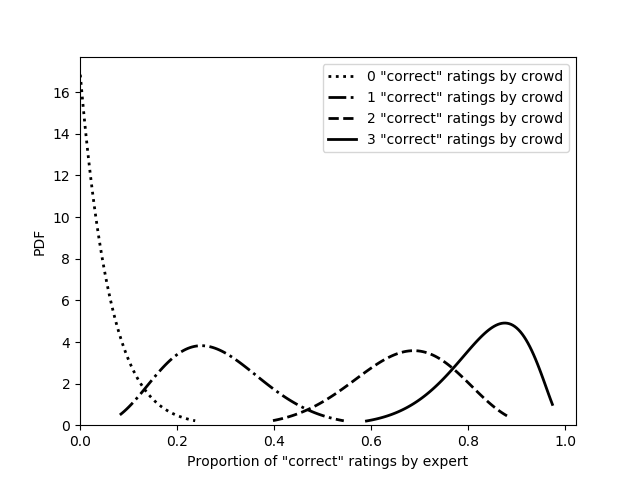
State-of-the-art models for multi-hop question answering typically augment large-scale language models like BERT with additional, intuitively useful capabilities such as named entity recognition, graph-based reasoning, and question decomposition. However, does their strong performance on popular multi-hop datasets really justify this added design complexity? Our results suggest that the answer may be no, because even our simple pipeline based on BERT, named \model, performs surprisingly well. Specifically, on HotpotQA, Quark outperforms these models on both question answering and support identification (and achieves performance very close to a RoBERTa model). Our pipeline has three steps: 1) use BERT to identify potentially relevant sentences \emph{independently} of each other; 2) feed the set of selected sentences as context into a standard BERT span prediction model to choose an answer; and 3) use the sentence selection model, now with the chosen answer, to produce supporting sentences. The strong performance of Quark resurfaces the importance of carefully exploring simple model designs before using popular benchmarks to justify the value of complex techniques.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Efficient One-Pass End-to-End Entity Linking for Questions
Belinda Z. Li, Sewon Min, Srinivasan Iyer, Yashar Mehdad, Wen-tau Yih,
MultiCQA: Zero-Shot Transfer of Self-Supervised Text Matching Models on a Massive Scale
Andreas Rücklé, Jonas Pfeiffer, Iryna Gurevych,

Small but Mighty: New Benchmarks for Split and Rephrase
Li Zhang, Huaiyu Zhu, Siddhartha Brahma, Yunyao Li,