KGPT: Knowledge-Grounded Pre-Training for Data-to-Text Generation
Wenhu Chen, Yu Su, Xifeng Yan, William Yang Wang
Language Generation Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
Data-to-text generation has recently attracted substantial interests due to its wide applications. Existing methods have shown impressive performance on an array of tasks. However, they rely on a significant amount of labeled data for each task, which is costly to acquire and thus limits their application to new tasks and domains. In this paper, we propose to leverage pre-training and transfer learning to address this issue. We propose a knowledge-grounded pre-training (KGPT), which consists of two parts, 1) a general knowledge-grounded generation model to generate knowledge-enriched text. 2) a pre-training paradigm on a massive knowledge-grounded text corpus crawled from the web. The pre-trained model can be fine-tuned on various data-to-text generation tasks to generate task-specific text. We adopt three settings, namely fully-supervised, zero-shot, few-shot to evaluate its effectiveness. Under the fully-supervised setting, our model can achieve remarkable gains over the known baselines. Under zero-shot setting, our model without seeing any examples achieves over 30 ROUGE-L on WebNLG while all other baselines fail. Under the few-shot setting, our model only needs about one-fifteenth as many labeled examples to achieve the same level of performance as baseline models. These experiments consistently prove the strong generalization ability of our proposed framework\footnote{\url{https://github.com/wenhuchen/KGPT}}.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
An Empirical Investigation Towards Efficient Multi-Domain Language Model Pre-training
Kristjan Arumae, Qing Sun, Parminder Bhatia,
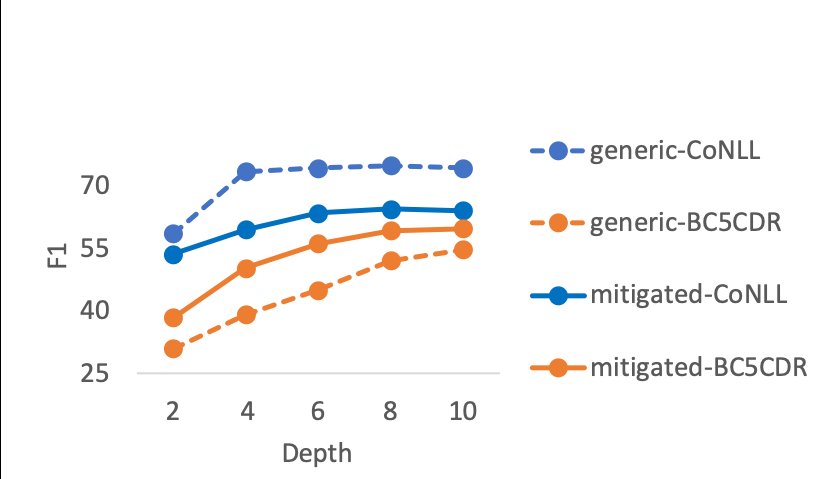
Zero-Shot Cross-Lingual Transfer with Meta Learning
Farhad Nooralahzadeh, Giannis Bekoulis, Johannes Bjerva, Isabelle Augenstein,
Pre-training for Abstractive Document Summarization by Reinstating Source Text
Yanyan Zou, Xingxing Zhang, Wei Lu, Furu Wei, Ming Zhou,
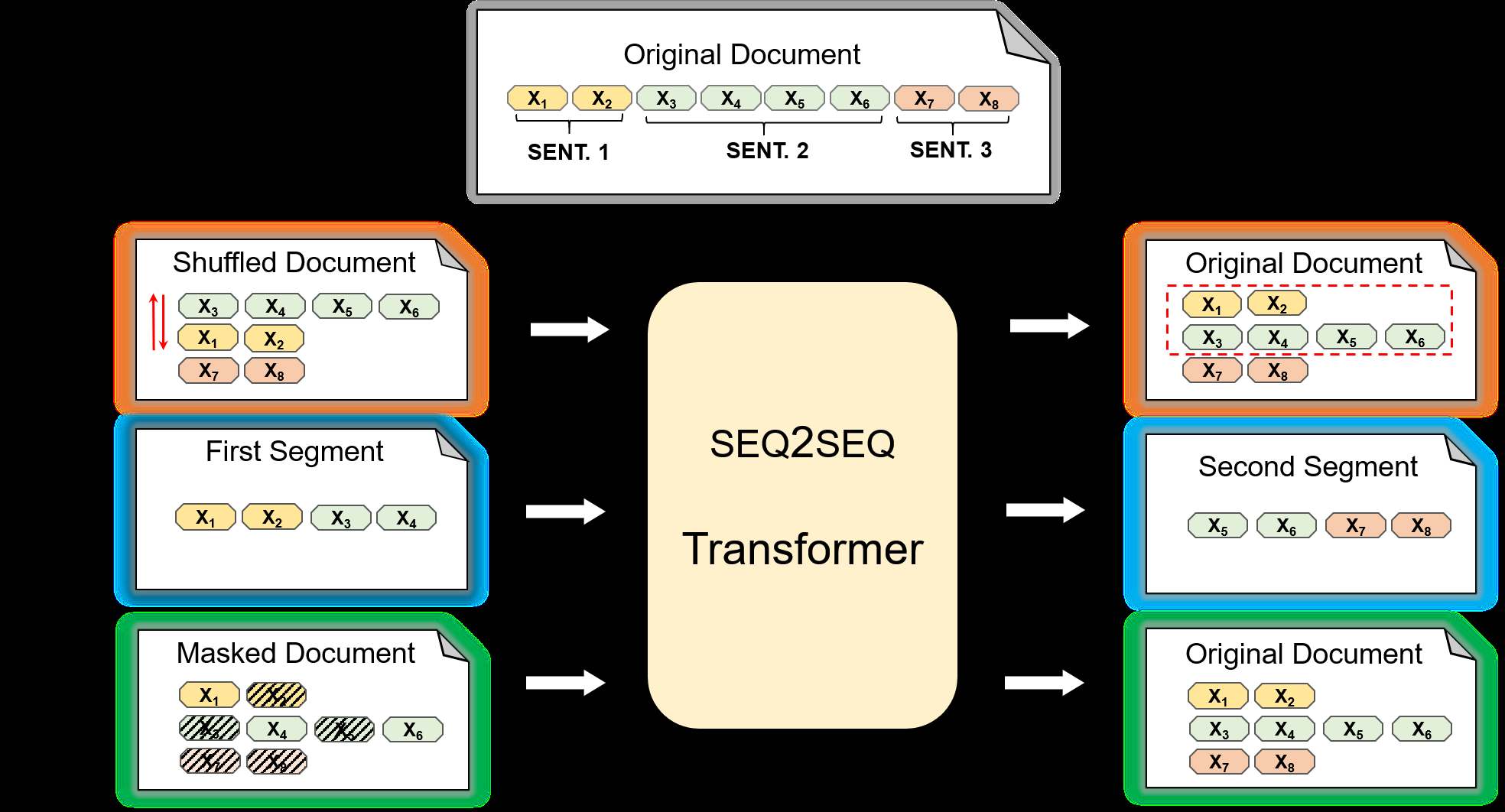
MEGATRON-CNTRL: Controllable Story Generation with External Knowledge Using Large-Scale Language Models
Peng Xu, Mostofa Patwary, Mohammad Shoeybi, Raul Puri, Pascale Fung, Anima Anandkumar, Bryan Catanzaro,