Sparse Parallel Training of Hierarchical Dirichlet Process Topic Models
Alexander Terenin, Måns Magnusson, Leif Jonsson
Machine Learning for NLP Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
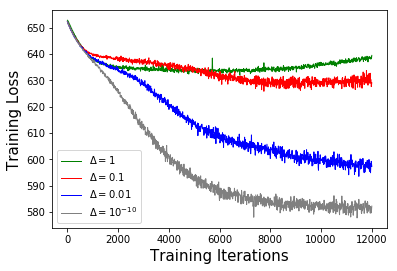
To scale non-parametric extensions of probabilistic topic models such as Latent Dirichlet allocation to larger data sets, practitioners rely increasingly on parallel and distributed systems. In this work, we study data-parallel training for the hierarchical Dirichlet process (HDP) topic model. Based upon a representation of certain conditional distributions within an HDP, we propose a doubly sparse data-parallel sampler for the HDP topic model. This sampler utilizes all available sources of sparsity found in natural language - an important way to make computation efficient. We benchmark our method on a well-known corpus (PubMed) with 8m documents and 768m tokens, using a single multi-core machine in under four days.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Tired of Topic Models? Clusters of Pretrained Word Embeddings Make for Fast and Good Topics too!
Suzanna Sia, Ayush Dalmia, Sabrina J. Mielke,
Short Text Topic Modeling with Topic Distribution Quantization and Negative Sampling Decoder
Xiaobao Wu, Chunping Li, Yan Zhu, Yishu Miao,

Training for Gibbs Sampling on Conditional Random Fields with Neural Scoring Factors
Sida Gao, Matthew R. Gormley,
Learning VAE-LDA Models with Rounded Reparameterization Trick
Runzhi Tian, Yongyi Mao, Richong Zhang,