The Multilingual Amazon Reviews Corpus
Phillip Keung, Yichao Lu, György Szarvas, Noah A. Smith
Machine Translation and Multilinguality Short Paper

You can open the pre-recorded video in a separate window.
Abstract:
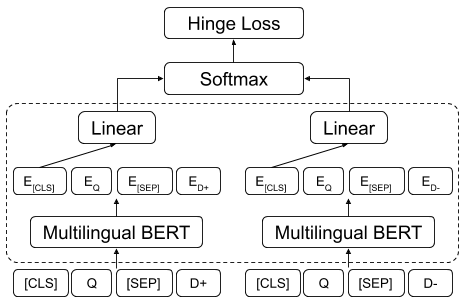
We present the Multilingual Amazon Reviews Corpus (MARC), a large-scale collection of Amazon reviews for multilingual text classification. The corpus contains reviews in English, Japanese, German, French, Spanish, and Chinese, which were collected between 2015 and 2019. Each record in the dataset contains the review text, the review title, the star rating, an anonymized reviewer ID, an anonymized product ID, and the coarse-grained product category (e.g., 'books', 'appliances', etc.) The corpus is balanced across the 5 possible star ratings, so each rating constitutes 20% of the reviews in each language. For each language, there are 200,000, 5,000, and 5,000 reviews in the training, development, and test sets, respectively. We report baseline results for supervised text classification and zero-shot cross-lingual transfer learning by fine-tuning a multilingual BERT model on reviews data. We propose the use of mean absolute error (MAE) instead of classification accuracy for this task, since MAE accounts for the ordinal nature of the ratings.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
CCAligned: A Massive Collection of Cross-Lingual Web-Document Pairs
Ahmed El-Kishky, Vishrav Chaudhary, Francisco Guzmán, Philipp Koehn,


Improving Multilingual Models with Language-Clustered Vocabularies
Hyung Won Chung, Dan Garrette, Kiat Chuan Tan, Jason Riesa,
