Cross-Media Keyphrase Prediction: A Unified Framework with Multi-Modality Multi-Head Attention and Image Wordings
Yue Wang, Jing Li, Michael Lyu, Irwin King
Computational Social Science and Social Media Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
Social media produces large amounts of contents every day. To help users quickly capture what they need, keyphrase prediction is receiving a growing attention. Nevertheless, most prior efforts focus on text modeling, largely ignoring the rich features embedded in the matching images. In this work, we explore the joint effects of texts and images in predicting the keyphrases for a multimedia post. To better align social media style texts and images, we propose: (1) a novel Multi-Modality MultiHead Attention (M3H-Att) to capture the intricate cross-media interactions; (2) image wordings, in forms of optical characters and image attributes, to bridge the two modalities. Moreover, we design a unified framework to leverage the outputs of keyphrase classification and generation and couple their advantages. Extensive experiments on a large-scale dataset newly collected from Twitter show that our model significantly outperforms the previous state of the art based on traditional attention mechanisms. Further analyses show that our multi-head attention is able to attend information from various aspects and boost classification or generation in diverse scenarios.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
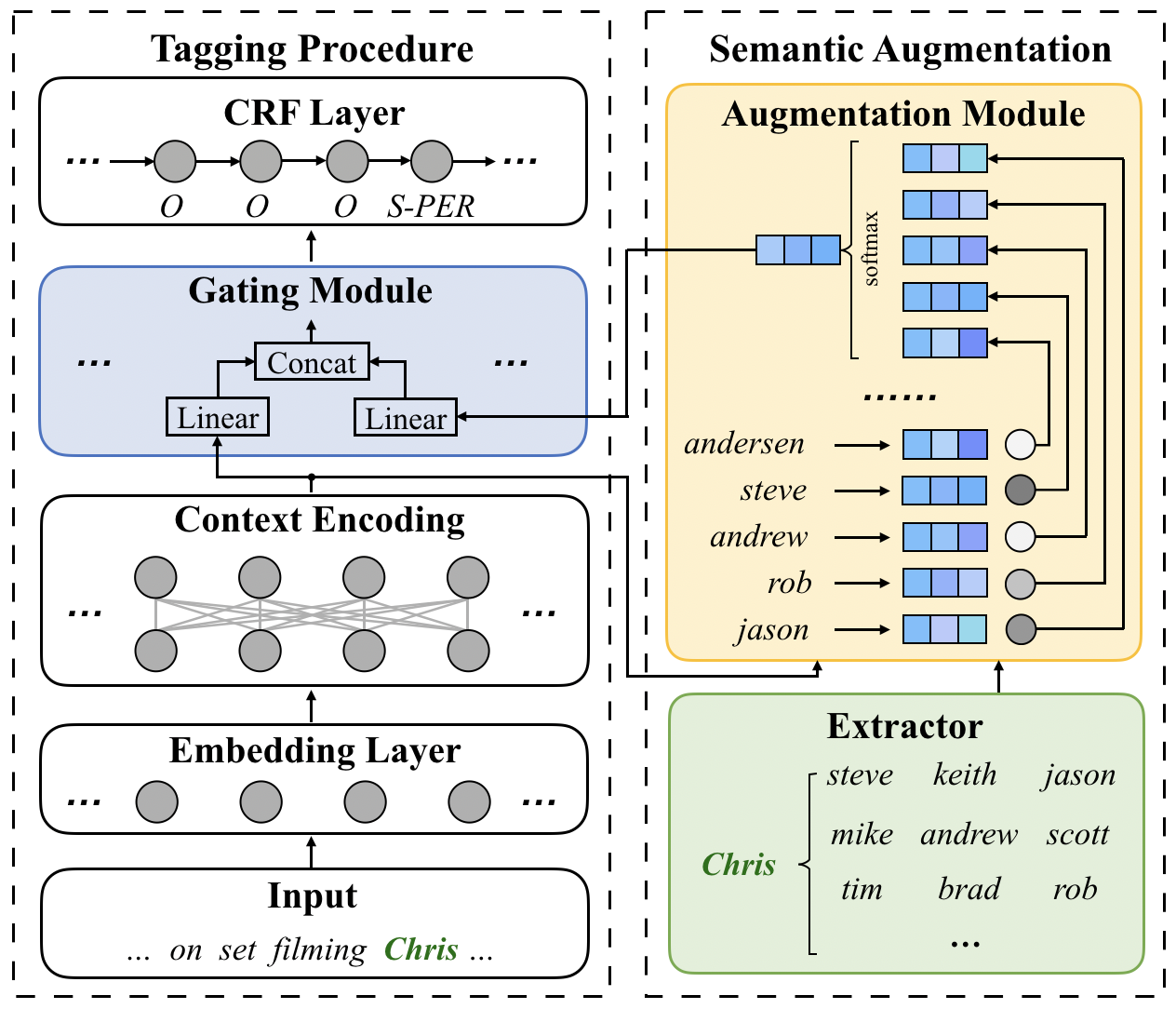
Multi-resolution Annotations for Emoji Prediction
Weicheng Ma, Ruibo Liu, Lili Wang, Soroush Vosoughi,

VMSMO: Learning to Generate Multimodal Summary for Video-based News Articles
Mingzhe Li, Xiuying Chen, Shen Gao, Zhangming Chan, Dongyan Zhao, Rui Yan,

Hashtags, Emotions, and Comments: A Large-Scale Dataset to Understand Fine-Grained Social Emotions to Online Topics
Keyang Ding, Jing Li, Yuji Zhang,
Named Entity Recognition for Social Media Texts with Semantic Augmentation
Yuyang Nie, Yuanhe Tian, Xiang Wan, Yan Song, Bo Dai,