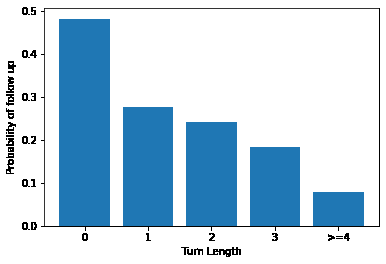
Counterfactual Off-Policy Training for Neural Dialogue Generation
Qingfu Zhu, Wei-Nan Zhang, Ting Liu, William Yang Wang
Dialog and Interactive Systems Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
Open-domain dialogue generation suffers from the data insufficiency problem due to the vast size of potential responses. In this paper, we propose to explore potential responses by counterfactual reasoning. Given an observed response, the counterfactual reasoning model automatically infers the outcome of an alternative policy that could have been taken. The resulting counterfactual response synthesized in hindsight is of higher quality than the response synthesized from scratch. Training on the counterfactual responses under the adversarial learning framework helps to explore the high-reward area of the potential response space. An empirical study on the DailyDialog dataset shows that our approach significantly outperforms the HRED model as well as the conventional adversarial learning approaches.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Learning to Contrast the Counterfactual Samples for Robust Visual Question Answering
Zujie Liang, Weitao Jiang, Haifeng Hu, Jiaying Zhu,

Task-Completion Dialogue Policy Learning via Monte Carlo Tree Search with Dueling Network
Sihan Wang, Kaijie Zhou, Kunfeng Lai, Jianping Shen,
Generating Dialogue Responses from a Semantic Latent Space
Wei-Jen Ko, Avik Ray, Yilin Shen, Hongxia Jin,
Neural Conversational QA: Learning to Reason vs Exploiting Patterns
Nikhil Verma, Abhishek Sharma, Dhiraj Madan, Danish Contractor, Harshit Kumar, Sachindra Joshi,