Universal Natural Language Processing with Limited Annotations: Try Few-shot Textual Entailment as a Start
Wenpeng Yin, Nazneen Fatema Rajani, Dragomir Radev, Richard Socher, Caiming Xiong
Semantics: Sentence-level Semantics, Textual Inference and Other areas Long Paper

Abstract:
A standard way to address different NLP problems is by first constructing a problem-specific dataset, then building a model to fit this dataset. To build the ultimate artificial intelligence, we desire a single machine that can handle diverse new problems, for which task-specific annotations are limited. We bring up textual entailment as a unified solver for such NLP problems. However, current research of textual entailment has not spilled much ink on the following questions: (i) How well does a pretrained textual entailment system generalize across domains with only a handful of domain-specific examples? and (ii) When is it worth transforming an NLP task into textual entailment? We argue that the transforming is unnecessary if we can obtain rich annotations for this task. Textual entailment really matters particularly when the target NLP task has insufficient annotations. Universal NLP can be probably achieved through different routines. In this work, we introduce Universal Few-shot textual Entailment (UFO-Entail). We demonstrate that this framework enables a pretrained entailment model to work well on new entailment domains in a few-shot setting, and show its effectiveness as a unified solver for several downstream NLP tasks such as question answering and coreference resolution when the end-task annotations are limited.
Connected Papers in EMNLP2020
Similar Papers

New Protocols and Negative Results for Textual Entailment Data Collection
Samuel R. Bowman, Jennimaria Palomaki, Livio Baldini Soares, Emily Pitler,

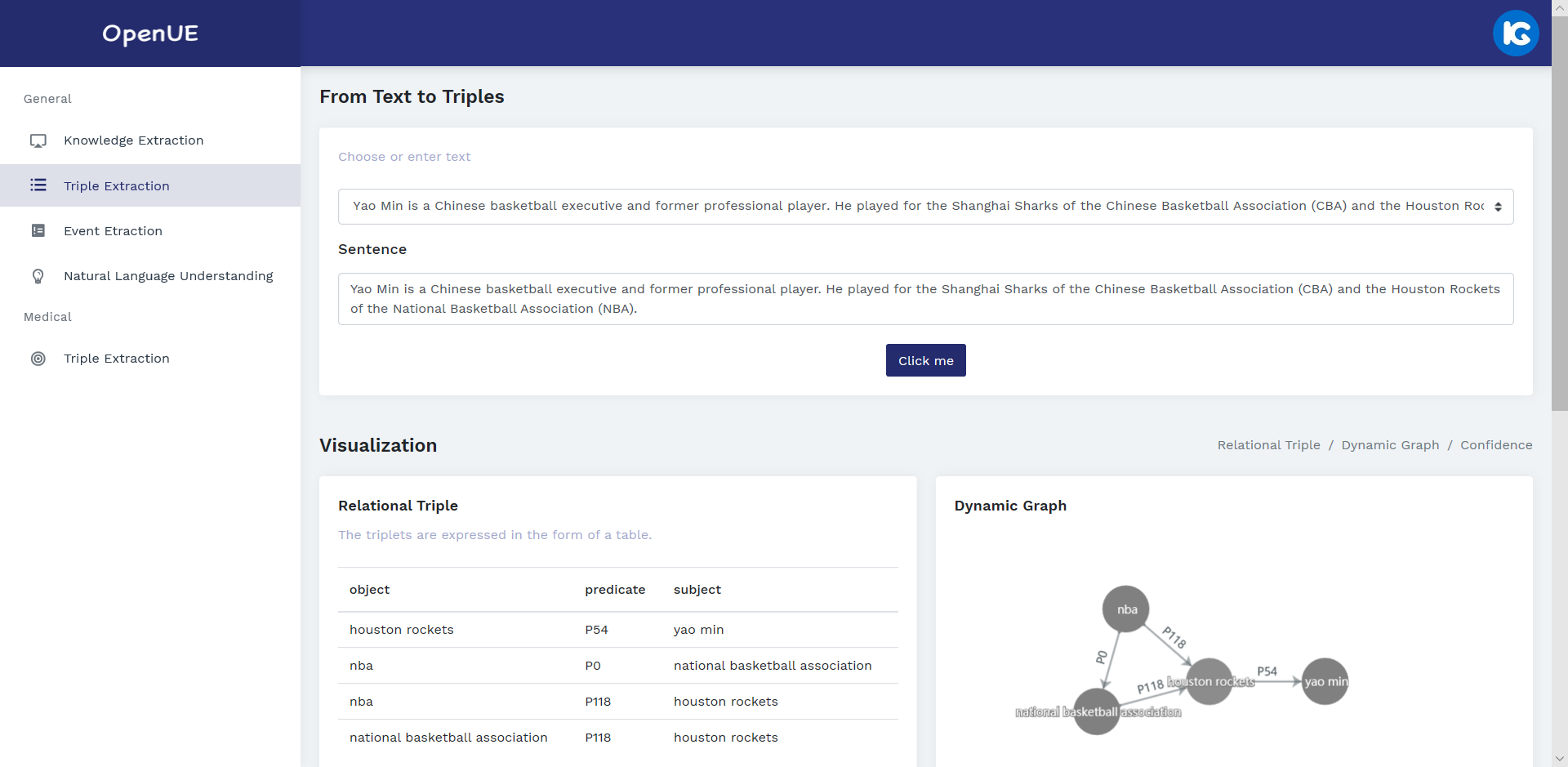
OpenUE: An Open Toolkit of Universal Extraction from Text
Ningyu Zhang, Shumin Deng, Zhen Bi, Haiyang Yu, Jiacheng Yang, Mosha Chen, Fei Huang, Wei Zhang, Huajun Chen,