Wikipedia2Vec: An Efficient Toolkit for Learning and Visualizing the Embeddings of Words and Entities from Wikipedia
Ikuya Yamada, Akari Asai, Jin Sakuma, Hiroyuki Shindo, Hideaki Takeda, Yoshiyasu Takefuji, Yuji Matsumoto
Demo Paper

Abstract:
The embeddings of entities in a large knowledge base (e.g., Wikipedia) are highly beneficial for solving various natural language tasks that involve real world knowledge. In this paper, we present Wikipedia2Vec, a Python-based open-source tool for learning the embeddings of words and entities from Wikipedia. The proposed tool enables users to learn the embeddings efficiently by issuing a single command with a Wikipedia dump file as an argument. We also introduce a web-based demonstration of our tool that allows users to visualize and explore the learned embeddings. In our experiments, our tool achieved a state-of-the-art result on the KORE entity relatedness dataset, and competitive results on various standard benchmark datasets. Furthermore, our tool has been used as a key component in various recent studies. We publicize the source code, demonstration, and the pretrained embeddings for 12 languages at https://wikipedia2vec.github.io/.
Similar Papers
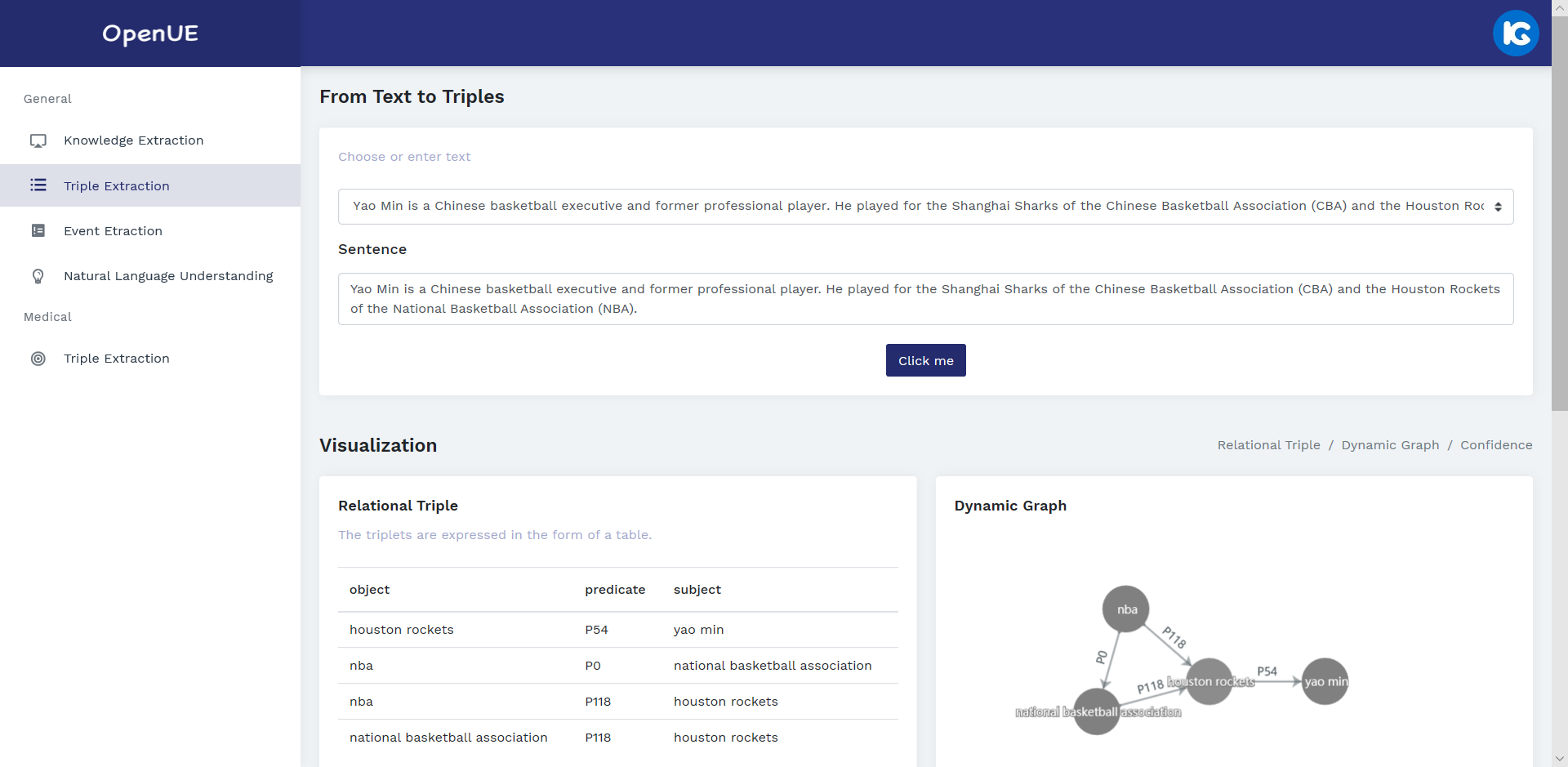
OpenUE: An Open Toolkit of Universal Extraction from Text
Ningyu Zhang, Shumin Deng, Zhen Bi, Haiyang Yu, Jiacheng Yang, Mosha Chen, Fei Huang, Wei Zhang, Huajun Chen,
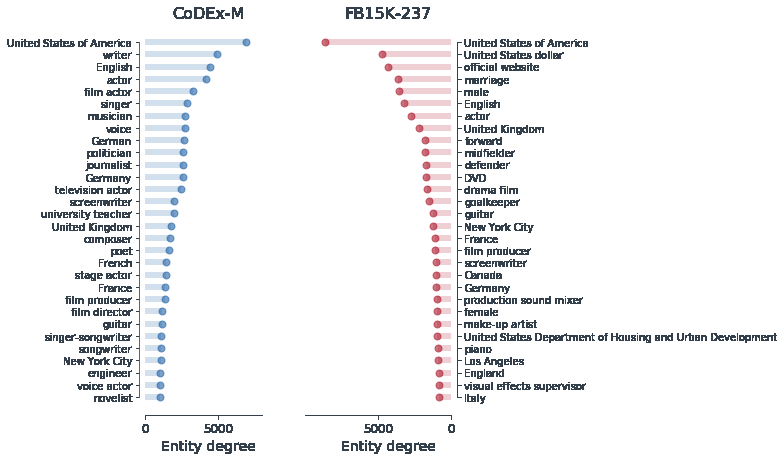
Design Challenges in Low-resource Cross-lingual Entity Linking
Xingyu Fu, Weijia Shi, Xiaodong Yu, Zian Zhao, Dan Roth,