Scaling Hidden Markov Language Models
Justin Chiu, Alexander Rush
Machine Learning for NLP Short Paper

You can open the pre-recorded video in a separate window.
Abstract:
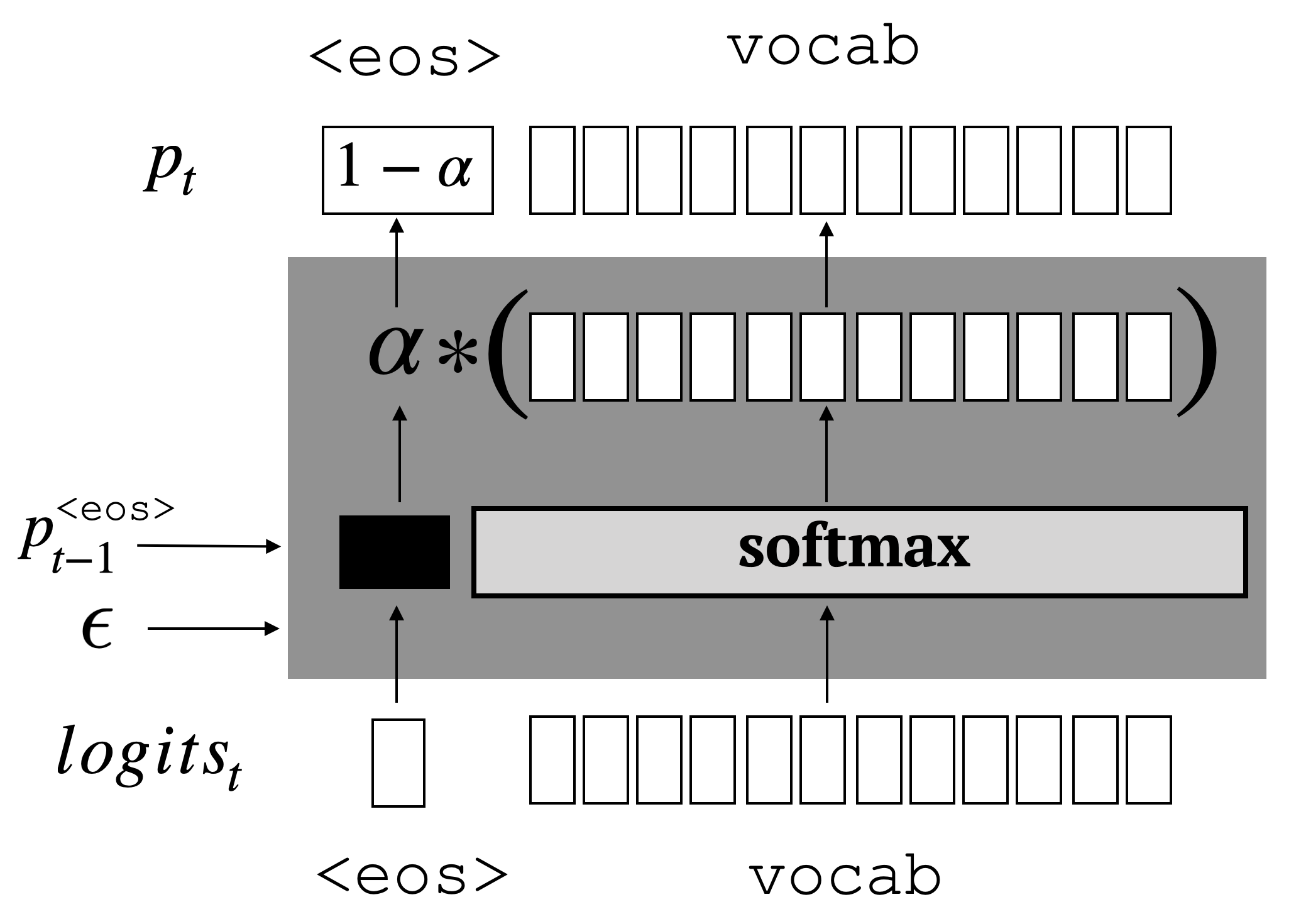
The hidden Markov model (HMM) is a fundamental tool for sequence modeling that cleanly separates the hidden state from the emission structure. However, this separation makes it difficult to fit HMMs to large datasets in modern NLP, and they have fallen out of use due to very poor performance compared to fully observed models. This work revisits the challenge of scaling HMMs to language modeling datasets, taking ideas from recent approaches to neural modeling. We propose methods for scaling HMMs to massive state spaces while maintaining efficient exact inference, a compact parameterization, and effective regularization. Experiments show that this approach leads to models that are much more accurate than previous HMMs and n-gram-based methods, making progress towards the performance of state-of-the-art NN models.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space
Chunyuan Li, Xiang Gao, Yuan Li, Baolin Peng, Xiujun Li, Yizhe Zhang, Jianfeng Gao,


Consistency of a Recurrent Language Model With Respect to Incomplete Decoding
Sean Welleck, Ilia Kulikov, Jaedeok Kim, Richard Yuanzhe Pang, Kyunghyun Cho,
AIN: Fast and Accurate Sequence Labeling with Approximate Inference Network
Xinyu Wang, Yong Jiang, Nguyen Bach, Tao Wang, Zhongqiang Huang, Fei Huang, Kewei Tu,
