META: Metadata-Empowered Weak Supervision for Text Classification
Dheeraj Mekala, Xinyang Zhang, Jingbo Shang
Information Retrieval and Text Mining Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
Recent advances in weakly supervised learning enable training high-quality text classifiers by only providing a few user-provided seed words. Existing methods mainly use text data alone to generate pseudo-labels despite the fact that metadata information (e.g., author and timestamp) is widely available across various domains. Strong label indicators exist in the metadata and it has been long overlooked mainly due to the following challenges: (1) metadata is multi-typed, requiring systematic modeling of different types and their combinations, (2) metadata is noisy, some metadata entities (e.g., authors, venues) are more compelling label indicators than others. In this paper, we propose a novel framework, META, which goes beyond the existing paradigm and leverages metadata as an additional source of weak supervision. Specifically, we organize the text data and metadata together into a text-rich network and adopt network motifs to capture appropriate combinations of metadata. Based on seed words, we rank and filter motif instances to distill highly label-indicative ones as “seed motifs”, which provide additional weak supervision. Following a bootstrapping manner, we train the classifier and expand the seed words and seed motifs iteratively. Extensive experiments and case studies on real-world datasets demonstrate superior performance and significant advantages of leveraging metadata as weak supervision.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers

Learning from Context or Names? An Empirical Study on Neural Relation Extraction
Hao Peng, Tianyu Gao, Xu Han, Yankai Lin, Peng Li, Zhiyuan Liu, Maosong Sun, Jie Zhou,

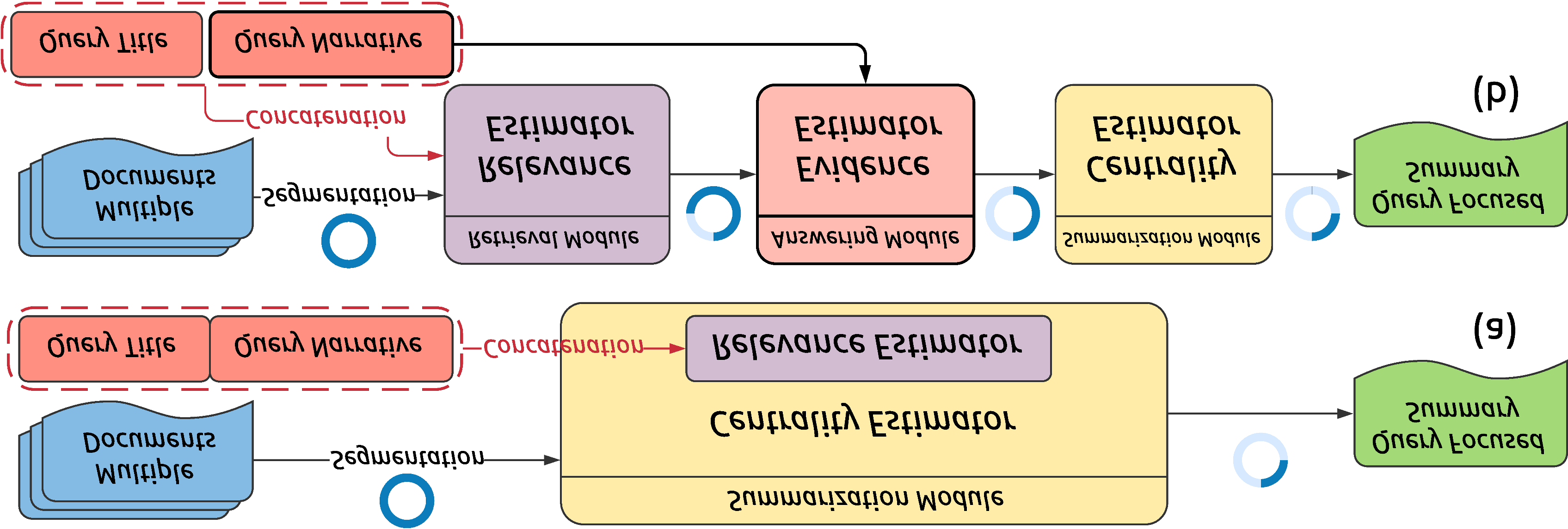
Named Entity Recognition for Social Media Texts with Semantic Augmentation
Yuyang Nie, Yuanhe Tian, Xiang Wan, Yan Song, Bo Dai,