Learning to Represent Image and Text with Denotation Graph
Bowen Zhang, Hexiang Hu, Vihan Jain, Eugene Ie, Fei Sha
Language Grounding to Vision, Robotics and Beyond Long Paper

You can open the pre-recorded video in a separate window.
Abstract:
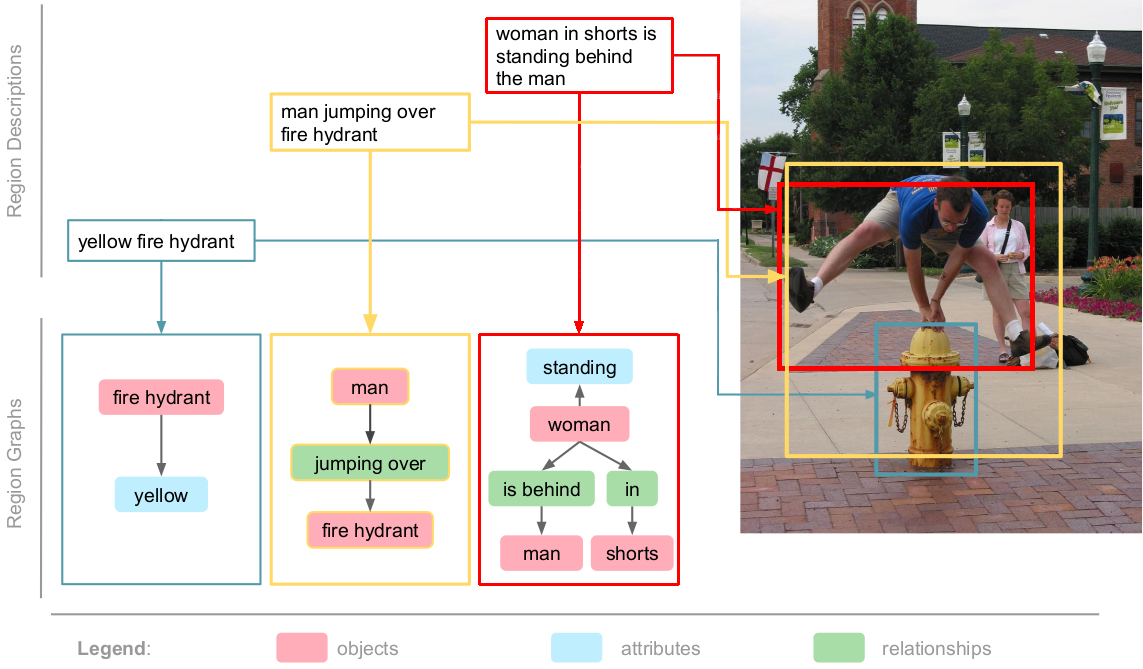
Learning to fuse vision and language information and representing them is an important research problem with many applications. Recent progresses have leveraged the ideas of pre-training (from language modeling) and attention layers in Transformers to learn representation from datasets containing images aligned with linguistic expressions that describe the images. In this paper, we propose learning representations from a set of implied, visually grounded expressions between image and text, automatically mined from those datasets. In particular, we use denotation graphs to represent how specific concepts (such as sentences describing images) can be linked to abstract and generic concepts (such as short phrases) that are also visually grounded. This type of generic-to-specific relations can be discovered using linguistic analysis tools. We propose methods to incorporate such relations into learning representation. We show that state-of-the-art multimodal learning models can be further improved by leveraging automatically harvested structural relations. The representations lead to stronger empirical results on downstream tasks of cross-modal image retrieval, referring expression, and compositional attribute-object recognition. Both our codes and the extracted denotation graphs on the Flickr30K and the COCO datasets are publically available on https://sha-lab.github.io/DG.
NOTE: Video may display a random order of authors.
Correct author list is at the top of this page.
Connected Papers in EMNLP2020
Similar Papers
Exploiting Structured Knowledge in Text via Graph-Guided Representation Learning
Tao Shen, Yi Mao, Pengcheng He, Guodong Long, Adam Trischler, Weizhu Chen,

Distilling Structured Knowledge for Text-Based Relational Reasoning
Jin Dong, Marc-Antoine Rondeau, William L. Hamilton,
Asking without Telling: Exploring Latent Ontologies in Contextual Representations
Julian Michael, Jan A. Botha, Ian Tenney,
An Unsupervised Joint System for Text Generation from Knowledge Graphs and Semantic Parsing
Martin Schmitt, Sahand Sharifzadeh, Volker Tresp, Hinrich Schütze,